
1
前言
参考《数据库系统概论》 尚硅谷Mysql教程
Mysql概述
MySQL是最流行的关系型数据库管理系统,数据库(Database)是按照数据结
构来组织、存储和管理数据的仓库,所谓的关系型数据库,是建立在关系模型
基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据
数据库基本概念
- Data 描述事物的符号记录
- DB(database) 存储数据的仓库,保存一系列有组织的数据
- DBMS(Database Management System) 可以操纵DB
- DBS DB和DBMS的总体描述
关系模型
关系模型由一组关系组成,每个关系的数据结构是一张规范化的二维表,
一般的描述方式为 关系名(属性1,属性2,···,属性n),关系的每
一个属性值都必须是一个不可分的数据项,也就是说不允许表中还有表
,关系模型的数据操纵主要包括查询、插入、删除和更新,这些操作都
需要满足关系的完整性约束条件
SQL
结构化查询语言(Structured Query Language)是关系数据库的标准语
言,包括查询、数据库模式创建、数据的删除修改等一些列功能,SQL语句
不区分大小写
- DQL 查询语句 主要由select组成
- DML 数据操作语言,主要由insert、update和delete组成
- DDL 数据定义语言,主要由create、alter、drop和truncate组成
- DCL 数据控制语言,主要由grant和revoke组成
- TCL 事务控制语句 主要由commit、rollback和savepoint组成
MySQL使用
MySQL基本命令
默认以分号作为命令结束
- 显示所有数据库,mysql保存用户信息,information_schema保存原数据
1
2
3
4
5
6
7
8
9
10
11
12mysql> show databases;
+--------------------+
| Database |
+--------------------+
| gaoming |
| information_schema |
| mysql |
| performance_schema |
| sakila |
| sys |
| world |
+--------------------+ - 切换数据库
1
mysql> use gaoming;
- 显示数据库中的所有表,如果没进入gaoming则需要加from gaoming
1
2
3
4
5
6
7mysql> show tables;
+-------------------+
| Tables_in_gaoming |
+-------------------+
| gao |
| person |
+-------------------+ - 查看当前处于哪个数据库
1
2
3
4
5
6mysql> select database();
+------------+
| database() |
+------------+
| gaoming |
+------------+ - 创建一个表
1
2create table suinfo(
id int,name varchar(20)); - 查看表结构
1
2
3
4
5
6
7mysql> desc suinfo;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+ - 查看所有数据
1
mysql> select * from suinfo;
- 插入数据
1
mysql> insert into suinfo(id,name) values(1,'john');
- 修改数据
1
2
3
4
5
6
7
8
9ALTER TABLE mytable
ADD col CHAR(20);
ALTER TABLE mytable
DROP COLUMN col;
UPDATE mytable
SET col = val
WHERE id = 1; - 删除数据
1
mysql> delete from suinfo where id=1;
- 查看数据库版本,或者在cmd中输入 mysql –version
1
2
3
4
5
6mysql> select version();
+-----------+
| version() |
+-----------+
| 8.0.16 |
+-----------+ - SQL语句本身不区分大小写,Windows中字段和值也不区分大小写
1
2
3
4
5# 注释
SELECT *
FROM mytable; -- 注释
/* 注释1
注释2 */ - 主键的值是可以修改或者复用的,但是一般不这样
DQL
select的功能就是查询数据,不仅可以单表查询,也可以多表连接查询,还
可以进行子查询。select后的列表用于确定选择哪些列,where条件用于确
定选择哪些行,如果没有where条件默认选出所有行
- 基础查询
查询列表可以是表中的字段、常量、表达式、函数,查询结果是虚拟表单。
特殊字段可以加着重号`可以给字段起别名1
2
3
4
5select * from test;
#查询特定列
select name from test;
#可以增加where条件
select name from test where id>3;当使用select语句进行查询时,可以在语句中使用算术运算符形成算术表达式1
2
3
4
5
6
7select id as iid,name as mane from suinfo;
+------+------+
| iid | mane |
+------+------+
| 1 | ui |
| 2 | op |
+------+------+
- 对数值型数据列、变量、常量可以使用算术运算符
- 对日期型数据列、变量、常量可以使用算术运算符
- 可以在两个数据列之间使用算术运算符
1 | select id+5 from test; |
MySQL中不能用+将字符串连接起来,而是使用concat连接字符串
1 | select concat(username,'xx') from user; |
去除字段组合的重复值
1
select distinct id,name from test;
where子句可以控制只选择指定的行,该子句包含的是一个条件表达式,
所以可以使用基本的比较运算符,不仅可以比较数值的大小,也可以比较
字符串和日期,判断相等是=,不等是<>,赋值是:=
1
2
3
4select * from test where id between 2 and 7;
select * from test where 2 between id and teid;
select * from test where id in(1,3,5);
select * from test where 2 in(id,teid);like主要用于模糊查询,SQL语句中可以使用两个通配符,一个是_,表
示一个任意字符,另一个是%,表示任意多个字符,[]可匹配集合内的字符
,^可以表示否定1
2
3
4
5
6
7
8
9
10#以l开头的所有name
select * from test where name like 'l%';
#name为两个字符
select * from test where name like '__';
#使用转义字符,name以_开头
select * from test where name like '\_%';
#前者可能为null的话就不会查询出来,后者查询所有
select * from employes where name like '%%';
select * from employes;
SELECT * FROM mytable WHERE col LIKE '[^AB]%'; -- 不以 A 和 B 开头的任意文本is null用于判断某些值是否为空,不能使用=。ifnull 判断是否为null
如果为null就赋默认值1
2select * from test where name is null;
select id,ifnull(name,'vv') from test;如果where子句后有多个条件需要组合,SQL提供了and和or来组合这两个
条件,并提供not来对逻辑表达式求否
1
2select * from test where id>1 and name like'__';
select * from test where not name like '__';执行查询后的结果默认按插入顺序排列,如果需要查询的结果按照某列值
的大小排序,则可以使用order by。asc是由低到高,desc是由高到低,支
持别名,也支持多个条件排序逗号隔开1
2
3
4#默认是asc
select * from test order by id;
#如果需要多列排序,每列都要指定。第一列是首列,当第一列存在相同值第二列才起作用
select * from test order by id,name desc;
数据库函数
MySQL函数和编程语言中的函数很像,可以有多个输入但是只有一个输出。
函数可以分为单行函数和多行函数,单行函数对每行输入值单独计算,每
行得到一个计算结果返回给用户。多行函数对多行输入值整体计算,最后
只会得到一个结果 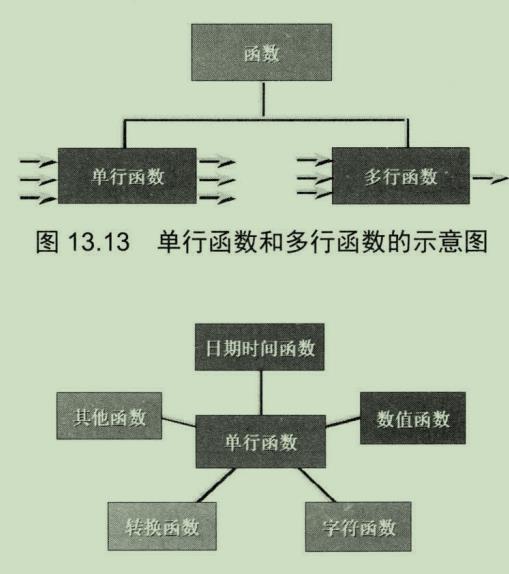
单行函数
- 参数可以是变量、常量或数据列。可以接收多个参数但只能返回一个
- 对每行单独起作用
- 可以改变参数的数据类型,支持嵌套使用,即内层函数的返回值是外层
函数的参数
1 | #字符长度 |
还提供了四个处理null的函数
- ifnull(exp1,exp2) 如果exp1为null,返回exp2,否则返回exp1
- nullif(exp1,exp2) 如果exp1与exp2相等返回null,否则返回exp1
- if(exp1,exp2,exp3) 如果exp1为true,不等于0且不等于null,则
返回exp2否则返回exp31
select if(1,2,3);
- isnull(exp1) 如果exp1为null则返回true,否则返回false
MySQL还提供了一个case函数,该函数是一个流程控制函数
1 | #第一种格式 |
upper变大写,lower变小写
substr(str,index),索引从1开始,substr(str,from,to),包含to
instr(str,strr) 获取起始索引,如果不匹配返回0
trim(str) 去掉前后空格
lpad(str,number,strr) 左填充字符
rpad(str,number,strr) 右填充字符
replace(str,str1,str2)1
2
3
4
5
6
7
8
9
10#获取字节数,一个汉字三个字节
select length('jhon');
select length('张三风');
select upper(name) from suinfo;
select substr('你好啊高明',3);
select instr('高明爱上了谁','爱');
select trim(' fsd ');
select trim('a' from 'aaafsdfdaaa');
select lpad('高明你好啊小老弟',15,'*');
select replace('周芷若爱上张无忌','周芷若','赵敏');数学函数
round(number) 四舍五入
round(number,2) 小数点后保留两位
ceil(number) 向上取整
floor(number) 向下取整
truncate(number,2) 小数点后阶段2位
mod(number1,number2) number1%number2日期函数
now() 返回当前日期+时间
curdate() 返回当前日期
curtime() 返回当前时间
year(now()) month(now()) monthname()
str_to_date(‘4-3 1999’,’%c-%d %Y’)=’1999-4-3’ 可以解析1
2
3
4
5
6mysql> select date_format(now(),'%y年%m月%d日');
+-----------------------------------+
| date_format(now(),'%y年%m月%d日') |
+-----------------------------------+
| 20年03月05日 |
+-----------------------------------+其他函数
version() database()
分组和组函数
组函数就是多行函数,组函数将一组记录作为一个整体计算,每组记录
返回一个结果而不是每行记录返回一个结果
- avg([distinct] exp) 计算多行exp的平均值,exp可以是变量、常量
或数据列,但是数据类型必须是数值型,还可以加上distinct表示无重复1
select avg(id) from test;
- count([distinct] exp) 计算多行exp的总条数,count可以是变量、
常量或数据列,数据类型可以是任意类型,用*号表示统计所有记录行数,
distinct表示不计算重复值,不会计算null1
2select count(*) from test;
select count(distinct id) from test; - max(exp) 计算多行中的最大值,exp可以是变量、常量或数据列,数据
类型可以是任意类型1
2select max(id) from test;
select max(name) from test; - min(exp) 与max相反
- sum([distinct] exp) 计算多行exp的总和,exp可以是变量、常量或
数据列,但是数据类型必须是数值型1
select sum(id) from test;
- 在默认情况下组函数会把所有记录当成一组,为了对记录显示分组可以
使用group by子句,group by后通常跟一个或多个列名,表示查询结果
根据一列或多列分组,当一列或多列的组合相同会当成一组1
2select sum(id) from test group by id;
select count(*) from test group by id,name; - 一旦使用组函数或者group by都将导致多条记录只有一条输出,如果
需要使用分组过滤则可以使用having子句,having子句后面也是跟一个
条件表达式,只有满足该条件表达式的分组才被选择,having和where
有如下区别
- 不能在where中过滤组,where仅用于过滤行,having用于过滤组
- 不能在where子句中使用组函数,having可以使用组函数
- GROUP BY 子句出现在WHERE子句之后,ORDER BY子句之前,行过滤优
先于分组过滤
1 | select * from test group by id having count(*)>1; |
多表连接查询
很多时候选择的数据不是来自一个表,而是来自多个表,这是就需要多表
连接查询,SQL99支持以下几种多表连接查询。多表连接可以理解为一个
二重循环,根据条件筛选符合的连接
- 交叉连接
- 自然连接
- 使用using子句的连接
- 使用on子句的连接
- 全外连接或左、右外连接
- 交叉连接 广义笛卡尔积,不需要任何连接条件
1
select s.*,t.nname from test s cross join tt t;
- 自然连接 自然连接会以两个表中的同名列作为连接条件,如果没有
同名列则与交叉连接效果一样。同名列的意思就是说连接条件是有相同
的列名,并且列的值也相同1
select s.* from test s natural join tt t;
- using子句连接 using子句可以指定一列或多列,用于显示指定两个
表中的同列名作为连接条件,假设两个表中有超过一列的同列名,如果
使用natural join,则会把所有的同列名当成连接条件,使用using
子句就可以显示指定哪些同列名作为连接条件1
select s.* from test s join tt t using(name);
- on子句连接 这是最常用的连接方式,将连接条件放在on子句中指定,
每个on子句只指定一个连接条件,如果要进行N表连接,则需要有N-1个
join .. on对1
select s.* from test s join tt t on s.id=t.id;
- 左、右、全外连接 分别使用left join,right join,full join,这
三种外连接的连接条件一样可以使用on子句来指定,MySQL目前不支持全
外连接1
2
3
4#右外连接,右表的记录会全部显示出来,左表只显示满足条件的记录,左边不足的地方用null显示
select s.*,t.id from test s right join tt t on s.id<t.id;
#左外连接
select s.*,t.id from test s left join tt t on s.id<t.id; - 内连接 也就是符合条件就显示
1
select s.*,t.id from test s inner join tt t on s.id<t.id;
子查询
子查询就是在查询语句中嵌套另一个查询,子查询可以支持多层嵌套,对于
一个普通的查询语句而言,子查询可以出现在两个位置
- 出现在from语句后当成数据表,这种用法也被称为行内视图,因为该子
查询的实质就是一个临时视图 - 出现在where条件后作为过滤条件的值
使用子查询时要注意如下几点
- 子查询要用括号括起来
- 当把子查询当成数据表时(出现在from之后),可以为该子查询起别名,尤
其作为前缀来限定数据列时,必须给子查询起别名 - 把子查询当成过滤条件时,将子查询放在比较运算符的右边,这样可以
增强查询的可读性 - 把子查询当成过滤条件时,单行子查询使用单行运算符,多行子查询使用
多行运算符
1 | #将子查询当成数据表 |
判断子查询的结果是否存在,若存在返回1不存在返回0
1 | select exist(select id from employee); |
集合运算
select语句的查询结果是一个包含多条数据的结果集,类似于数学中的集合,可以进
行交、并和差运算。对于两个结果集进行集合运算必须满足如下条件
- 两个结果集所包含的数据列的数量必须相等
- 两个数据列所包含的数据类型必须一一对应
- union运算 取并集
1
select * from test union select id,name from tt;
- minus运算 MySQL并不支持差运算,不过可以借助子查询实现差运算
1
2
3
4#从test中减去与tt中相同的记录
select * from test minus select id,name from tt;
#使用子查询实现
select * from test where (id,name) not in (select id,name from tt); - intersect运算 MySQL并不支持交运算,可以借助多表连接查询实现注意如果intersect运算的两个select子句都包含where条件,那么将intersect
1
2
3#两个数据列的数量想等,数据类型一一对应
select * from test intersect select id,name from tt;
select * from test t join tt s on (t.id=s.id and t.name=s.name);
运算改写成多表连接查询后还需要将两个where条件进行and运算1
2
3
4select * from test where id<4 intersect select id,name from tt where name
like '%fd';
select * from test t join tt s on(t.id=s.id and t.name =s.name) where
(t.id<4 and s.name like '%fd');
DML
与DDL操纵数据表不同,DML主要操作数据表里的数据,包含插入删除和修改
- 插入数据,一次只能插入一条数据
1
2
3
4
5
6
7
8
9
10
11
12#表名后是所以列名,列名后是相应的值
insert into test(id,name) values(1,'xyz');
#部分列名,其余列名为null,注意id是primary,所以不能替换为name
insert into test(id) values(2);
#也可以省略列名
insert into test values(3,'lkj');
#扩展语法,可以同时插入多个值
insert into test values(5,'lkj'),(6,'va');
#根据外键约束规则,外键列的值必须是主表中的值,不过可以为null
insert into fortest values(3/5/6);
#可是使用带子查询的插入语句,一次插入多条记录
insert into test(id) select iid from tabb; - 修改语句
1
2#where是修改的条件,也可以一次修改多列
update suinfo set name='mn' where id=7; - 删除语句
delete可以加where,truncate 不能加where,可以实现一次删除多行当
主表被从表参照时,主表记录不能被删除,只有先将从表参照的所有主表
的数据删除后才可以删除主表的数据。还有一种情况就是定义外键约束时
定义了主表记录和从表记录的级联删除on delete cascade或者使用on
delete set null指定当主表记录删除时从表参照的主表记录列设置为null1
2mysql> delete from suinfo where id=5;
truncate table suinfo;
DDL
操作数据库对象,包括创建删除和修改 
- 创建库
1
2mysql> create database book default character set utf8mb4;
Query OK, 1 row affected (0.04 sec) - 删除库
1
2mysql> drop database book;
Query OK, 0 rows affected (0.10 sec) - 创建表

1
2
3
4create table 表名(
#列名 列的类型
id int,price decimal,name varchar(20),desc text,img blog
); - 表的修改
可以修改列名和类型,一次只能修改一个列定义1
2
3
4#修改列名
mysql> alter table suu change nuid nnid int;
#修改列类型
mysql> alter table suu modify nnid varchar(20); - 添加新列,需要注意如果数据表中已经有数据,除非给新列指定默认值,
否则新增的数据列不可指定非空约束,因为已有的数据在新列上一定是空的1
2mysql> alter table suu add
(id int,name varchar(20) default 'xxx'); - 删除新列
1
mysql> alter table suu drop id;
- 修改表名
1
2mysql> alter table suu rename to su;
Query OK, 0 rows affected (0.03 sec) - 表的删除
1
2
3
4
5
6#表的结构也被删除
mysql> drop table su;
#只删除数据,不删除表的结构,只能一次性删除所有数据
truncate table su;
#也是删除所有数据,注意如果主键是自增的那么会从之前最大的主键值下一个开始自增
delete from te; - 表的复制
1
2
3
4
5
6
7#仅仅复制表的结构
mysql> create table copy like suinfo;
Query OK, 0 rows affected (0.06 sec)
#复制表的结构和数据,也可以复制部分数据
mysql> create table copy select * from suinfo;
Query OK, 6 rows affected (0.04 sec)
Records: 6 Duplicates: 0 Warnings: 0
常见约束
所有的关系数据库都支持对数据表使用约束,约束是在表上强制执行的数据
校验规则,主要用于保证数据的完整性,除此以外当表中的数据存在相互依
赖时可以保护相关的数据不被删除。可以分为单列约束和多列约束,指定约
束有两个时机,可以在创建表的同时为相应的数据列指定约束,或创建表后
以修改表的方式来增加约束
- not null 非空约束,该字段不能为空
- primary key 主键保证唯一性并且非空
- unique 字段值具有唯一性但是可以为空
- foreign key 外键用于限制两个表的关系保证该字段的值来自主表的关
联列的值,在从表中添加外键约束用于引用主表某列的值
- 非空约束 所有数据类型的值都可以是null,只能作为列级约束使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14create table hehe
(
id int not null,
name varchar(20) default 'xyz' not null,
#默认就是空
gender varchar(2) null
);
#也可以修改表
alter table hehe
modify gender varchar(2) not null;
alter table hehe
modify id int(11) null;
alter table hehe
modify name varchar(3) default 'abc' null; - unique约束 唯一约束用于保证指定列或指定列组合不允许出现重复值,
但是可以出现null,在数据库中null不等于null。同一个表中可以建立多
个唯一约束,唯一约束也可以由多个列组成,如果不给唯一约束起名则默
认与列名相同,如果需要为多列组合约束或者为唯一约束指定约束名则只
能使用表级约束1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37create table test
(
id int not null,
#列级约束
name varchar(20) unique
);
create table test2
(
id int not null,
name varchar(20),
pass varchar(20),
#表级约束
unique(name),
#表级约束并制定约束名
constraint uk unique(pass)
);
create table test3
(
name varchar(20),
pass varchar(20),
#两列组合建立唯一约束,一般是要取表名,要不然删除没有名字无法将组合约束删除
constraint uuk unique(name,pass)
);
create table test4
(
name varchar(20),
pass varchar(20)
);
#表级约束语法也可以放在alter语句中,为两列组合建立唯一约束
alter table test4
add unique(name,pass);
#使用列级约束语法
alter table test4
modify pass varchar(30) unique;
# drop index 约束名
alter table test3
drop index uuk; - primary key 主键约束相当于非空约束和唯一约束,不能出现重复
值也不能出现null值,如果对多列组合建立唯一约束,则多列组合里每
一列都不能为空,每一个表中最多允许有一个主键,但是可以由多个列
组成,不管是否指定约束名,Mysql总是将所有主键约束命名为primary
很多数据库对主键列都支持自增长特性,如果某个数据列是整型并且是
主键列那么可以指定该列具有自增长功能,而且插入时不可以为该列指
定值,可以用null替代,数据由数据库自动生成1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29create table test
(
#主键约束,采用列级约束语法
id int primary key,
name varchar(20)
);
create table test2
(
id int,
name varchar(20),
#表级约束,不需要指定约束名
constraint primary key(id)
);
create table test3
(
id int,
name varchar(20),
#表级约束,不需要指定约束名
constraint primary key(id,name)
);
#删除主键约束
alter table test3
drop primary key;
#表级约束语法
alter table test3
add primary key(id,name);
#如果只是单独列增加主键约束可以使用modify
alter table test3
modify name varchar(200) primary key; - foregin key 外键约束用于保证一个或两个表之间的参照完整性,外键
是构建于一个表的两个字段或者两个表的两个字段之间的参照关系。子表外
键列的值必须在主表被参照列的范围之内,或者为空。子表参照的只能是主
表主键列或者是唯一键列,同一个表内可以拥有多个外键。外键约束通常用
于学生与老师之间的对应关系,外键约束不仅可以参照其他表也可以参照
自身,被称为自关联,比如一个部门的经理与员工。如果想定义删除主表
记录时将从表的记录也删除,则需要在外键约束的最后添加on delete
cascade或on delete set null,第一种是删除主表记录时将从表记
录全部级联删除,第二种是将外键设置为null1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57create table teacher
(
id int auto_increment primary key,
name varchar(20)
);
#Mysql并不支持这种列级语法
create table student
(
id int auto_increment primary key,
name varchar(20),
teacherid int references teacher(id)
);
#Mysql支持表级约束
create table student
(
id int auto_increment primary key,
name varchar(20),
teacherid int,
foreign key(teacherid) references teacher(id)
);
#constraint可以显示指定从表的名字
create table student
(
id int auto_increment primary key,
name varchar(20),
teacherid int,
constraint stuteach foreign key(teacherid) references
teacher(id)
);
#多列组合的外键约束必须使用表级语法
create table teacher
(
name varchar(20),
pass varchar(20),
primary key(name,pass)
);
create table student
(
name varchar(20),
pass varchar(20),
foreign key(name,pass) references
teacher(name,pass)
);
#删除外键约束,默认外键约束名是table_name_ibfk_n
alter table student
drop foreign key student_ibfk_1;
#增加外键约束
alter table student
add foreign key(name,pass) references
teacher(name,pass);
#自关联
create table test
(
id int auto_increment primary key,
namr varchar(20),
foreign key(id) references test(id)
);
索引
参考 https://www.cnblogs.com/whgk/p/6179612.html
索引用于快速找出某个列中有一特定值的行,如果不使用索引那么会从表的
第一行开始查找,如果表中查询的列有一个索引,那么就能快速到达指定位
置而不需要遍历整个数据表,Mysql索引的底层结构使用B+树和hash
索引的使用
- 优点 数据库表中的所有列都可以设置索引,加快查询速度
- 缺点 创建索引和维护索引需要消耗一定时间,随数据量增加耗时也会增加,
索引也需要占据空间,数据表中的数据有最大上限设置,如果有大量索引那么
索引文件可能比数据更先到达上限。当对表中的数据进行增加、删除修改时,
索引也需要动态维护
基于以上优点和缺点,对于经常更新的表应该较少使用索引,对经常用于查询
的字段创建索引,数据量小的表最好不要创建索引,有可能索引的效率还不如
直接遍历查询,对于值较少的字段不要创建索引,比如性别只有两种可能就不
需要,对值较多的字段可以创建索引
索引的分类
索引是在存储引擎中实现的,不同的存储引擎会用到不同的索引
- MyISAM和InnoDB存储引擎:支持HASH和BTREE索引
- MEMORY/HEAP存储引擎:支持HASH和BTREE索引
索引可以分为4类
- 单列索引 一个索引只包含一个列,但是一个表中可以有多个索引
- 普通索引 没有什么限制,允许在定义索引的列中插入重复值和空值
- 唯一索引 索引列中的值是唯一的,但是允许为空
- 主键索引 特殊的唯一索引,不允许有空值
- 组合索引 在表中多个字段组合上创建索引,只有在查询时使用这些字段的
左边字段索引才会被使用 - 全文索引 只有在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT类型
字段上使用全文索引 - 空间索引 对空间数据类型的字段建立索引,MySQL中的空间数据类型有四种
,GEOMETRY、POINT、LINESTRING、POLYGON
索引操作
创建表的同时可以创建索引,通常有两种方式。除此以外当在表上定义主键约束、
唯一约束和外键约束时,系统会自动为数据列创建对应的索引
1 | create table book( |
explain可以用来查看索引是否正在被使用,并输出所用的索引信息 
- possible_keys Mysql在搜索数据记录时可以选用的各个索引
- key 实际选用的索引
创建唯一索引
1 | create table book( |
注意要查看查询时使用的索引必须先向表中插入数据,如果查询一个不存在的
id值是不会使用索引的,内部应该是将所有已有的id保存起来,如果没有该
id值就不会查找 
接下来创建组合索引,也就是在多个字段创建索引
1 | create table book( |
组合索引遵循最左前缀,利用索引中最左边的列集来匹配行,这样的列级称为
最左前缀。例如这里使用id age name三个字段组合构成索引,索引行中就会
按照id age name来存放,可以通过(id,age,name) (id,age) (id)来查
询字段,如果不是以上三种就不会使用索引查询。这个部分有点问题,先鸽
着 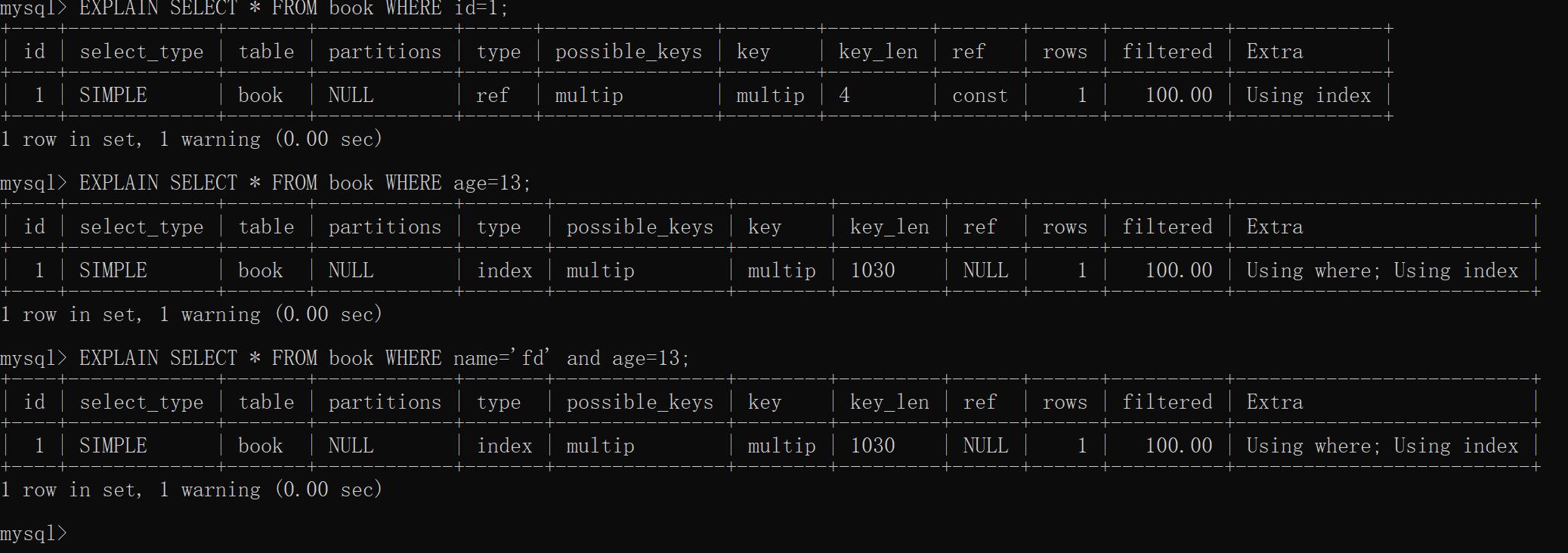
接下来创建全文索引,但只有MyISAM存储引擎支持FULLTEXT索引,并且只为
CHAR、VARCHAR和TEXT列服务。索引总是对整个列进行,不支持前缀索引
1 | create table book( |
全文搜索一般是从很长的字符串中通过关键字查找数据
1 | #关键字至少4个字符 |
接下来创建空间索引,空间索引也必须使用MyISAM引擎, 并且空间类型的字
段必须为非空
1 | create table book( |
还可以在已经存在的表上建立索引
1 | ALTER TABLE 表名 ADD[UNIQUE|FULLTEXT|SPATIAL][INDEX|KEY] [索引名] |
删除索引如下
1 | ALTER TABLE 表名 DROP INDEX 索引名 |
视图
视图像一个数据表但不是数据表,因为视图并不能存储数据,只是一个或多个
数据表中数据的逻辑显示。视图的本质就是一条被命名为sql的查询语句,有
以下好处。注意修改视图的数据时也会修改到基本数据表
- 可以限制对数据的访问
- 可以使复杂的查询变得简单
- 提供了数据的独立性
- 提供对先沟通数据的不同显示
1 | create or replace view viewname as subquery |
指定了witch check option关键字,这也就是说,更新后的每一条数据仍然
要满足创建视图时指定的where条件,插入和更新操作会失败,删除不会受影
响,具备以下特点的视图不可以修改
- distinct group by having union union all
- select 包含子查询
limit
搜索表结构中部分数据,limit position,count 。position表示起始查询
的位置,起始索引是0,count表示查询的数量。也可以直接 limit count
1 | #查询第二高的薪水 |
事务TCL
事务的创建
隐式事务没有明显开启和结束的标记
1 | mysql> set autocommit=0; |
编写事务(select insert update delete)
1 | begin; |
delete和truncate在事务中的区别
声明事务后
1 | delete from pperson; |
存储过程和函数
存储过程
一组预先编译好的sql语句的集合,理解成批处理语句,可以提高代码重用性
1 | delimiter 结束标记 $ |
参数模式
- in 可以作为输入,也就是需要调用时存入值
- out 可以作为输出。作为返回值
- inout 既可以作为输入也可以作为输出
1 | create procedure mm(in beauty varchar(20),in id varchar(20)) |
1 | create procedure my(in beautyname varchar(20),out boyname varchar(20),..) |
删除存储过程
1 | drop procedure my |
查看存储过程的结构
1 | show create procedure my; |
函数
存储过程可以有多个返回值,函数只有一个返回值
1 | create function 函数名(参数列表) returns 返回类型 |
查看函数
1 | show create function mm; |
删除函数
1 | drop function mm; |
游标
在存储过程中使用游标可以对一个结果集进行移动遍历。游标主要用于交互
式应用,其中用户需要对数据集中的任意行进行浏览和修改。使用游标的四
个步骤:
- 声明游标,这个过程没有实际检索出数据
- 打开游标
- 取出数据
- 关闭游标
1 | delimiter // |
触发器
触发器会在某个表执行以下语句时而自动执行:DELETE、INSERT、UPDATE。
触发器必须指定在语句执行之前还是之后自动执行,之前执行使用 BEFORE
关键字,之后执行使用 AFTER 关键字。BEFORE 用于数据验证和净化,
AFTER 用于审计跟踪,将修改记录到另外一张表中
INSERT 触发器包含一个名为 NEW 的虚拟表
1 | CREATE TRIGGER mytrigger AFTER INSERT ON mytable |
DELETE 触发器包含一个名为 OLD 的虚拟表,并且是只读的
UPDATE 触发器包含一个名为 NEW 和一个名为 OLD 的虚拟表,其中 NEW 是
可以被修改的,而 OLD 是只读的
MySQL 不允许在触发器中使用 CALL 语句,也就是不能调用存储过程
窗口函数
参考:猴子数据分析–通俗易懂的学会:SQL窗口函数
窗口函数的作用
窗口函数用于处理排名问题
- 每个部门按照业绩排名
- 找出每个部分排名前N个人
窗口函数的使用
窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理)
,可以对数据库数据进行实时分析处理
1 | <窗口函数> over (partition by <用于分组的列名> |
窗口函数可以分为两种:专用窗口函数和聚合函数
- 专用窗口函数 rank, dense_rank, row_number
- 聚合函数 sum. avg, count, max, min
因为窗口函数是对where和group by子句处理后的结果进行操作,所以窗口函数
原则上只能在select子句中使用
rank
如果想要在每个班级按照成绩排名 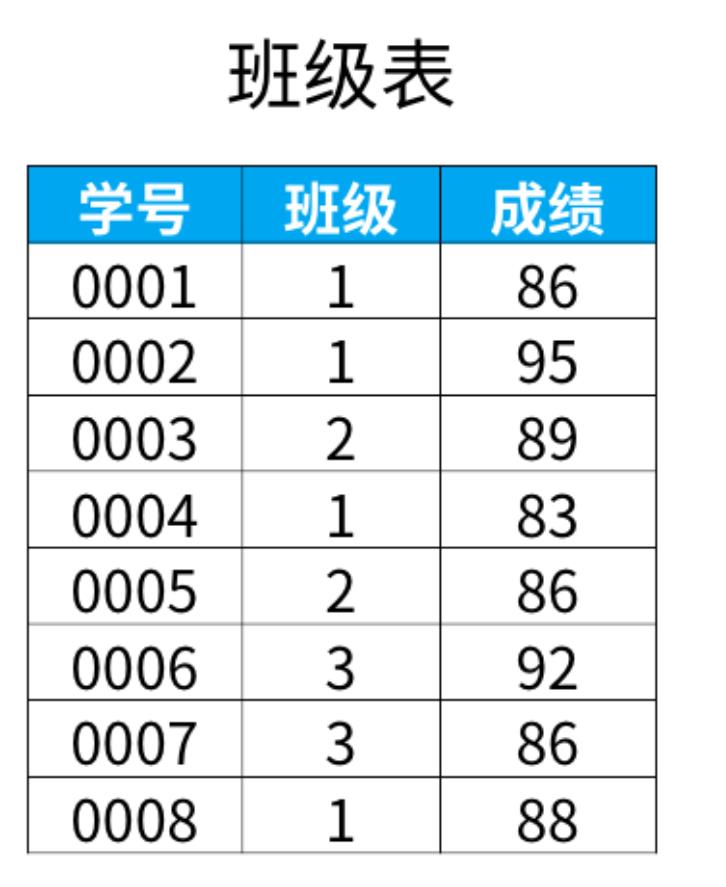
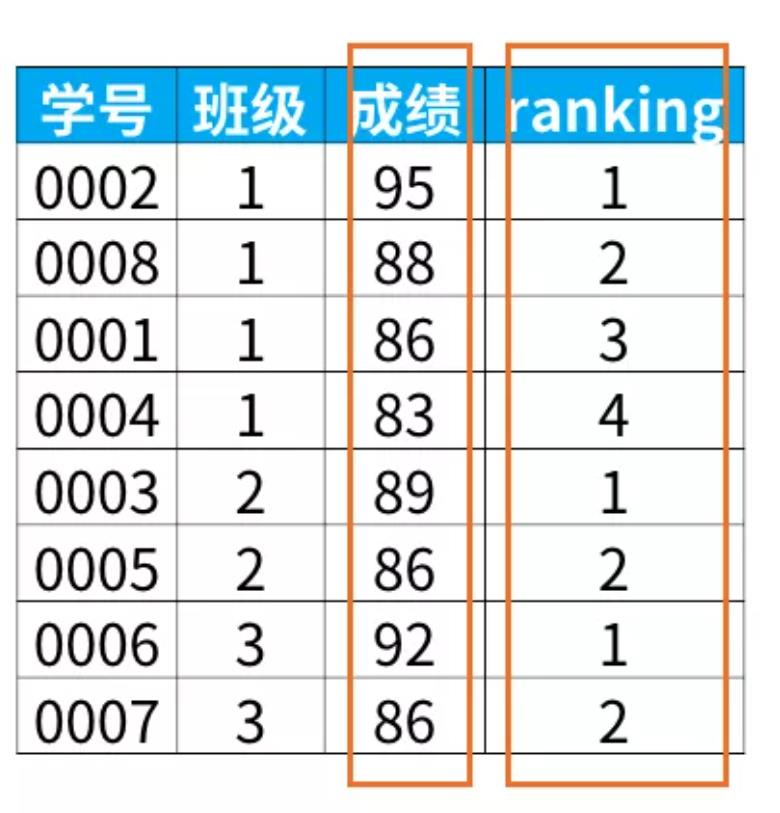
套模型的话写法如下,首先按照班级进行分组,然后在班级内对成绩进行排序
1 | select *, |
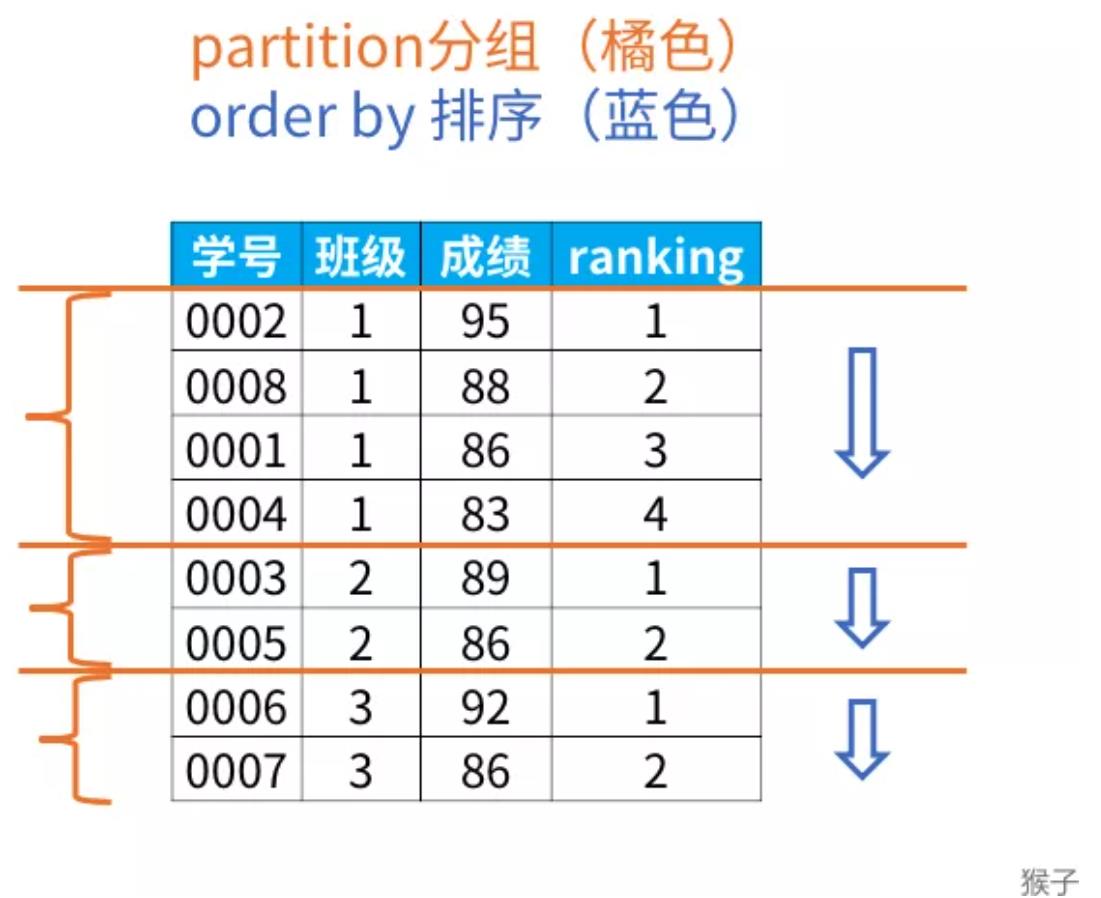
group by会改变表的行数,一行只有一个类别,而partiition by和rank
函数不会减少原表中的行数 
其他专业窗口函数
除了rank外还有dense_rank, row_number
1 | select *, |
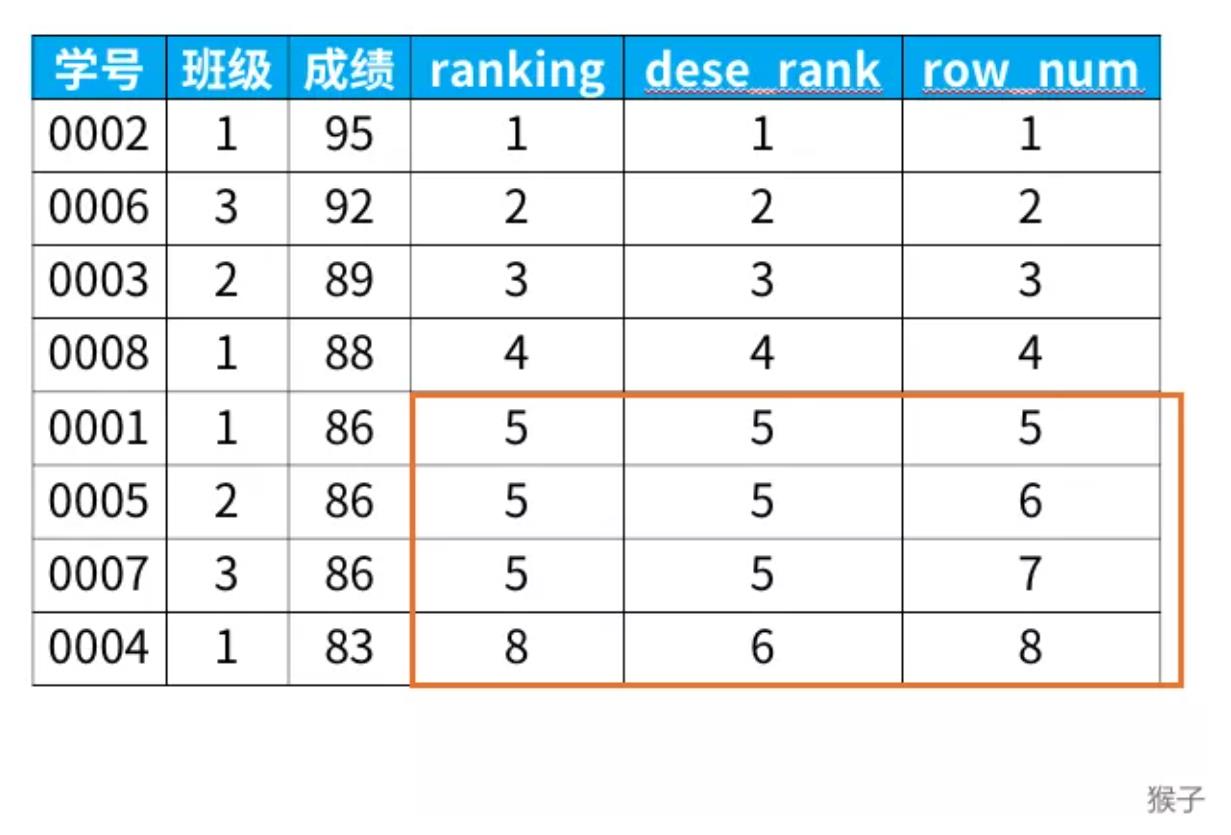
可以看出rank如果有并列名次的行会占据下一个名次的位置,dense_rank
如果有并列名次的行不会占用下一行的位置,row_number不会考虑并列名
次的情况
聚合函数作为窗口函数
只需要用聚合函数替代窗口函数的位置,但是括号中需要指定聚合的列名
1 | select *, |
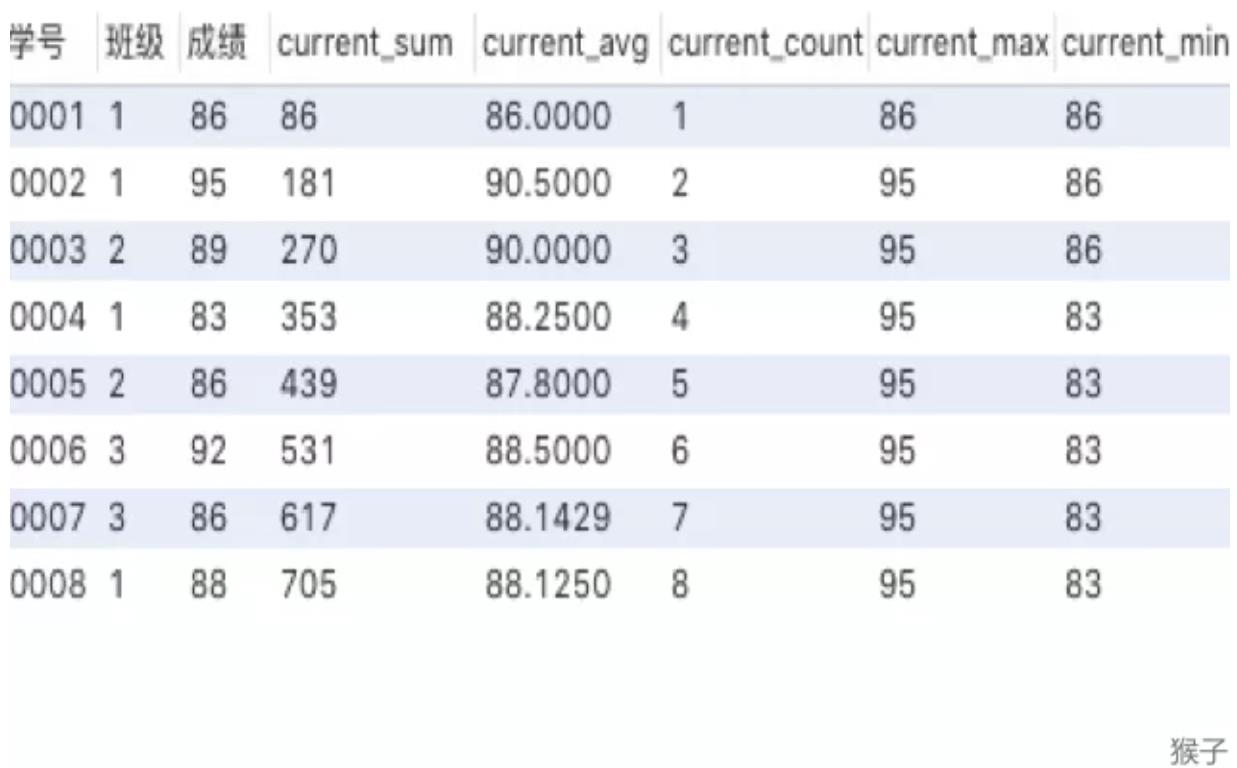
单独使用sum可以发现是对自身记录及以上的数据进行求和,求平均、计数、最大
和最小值也是如此 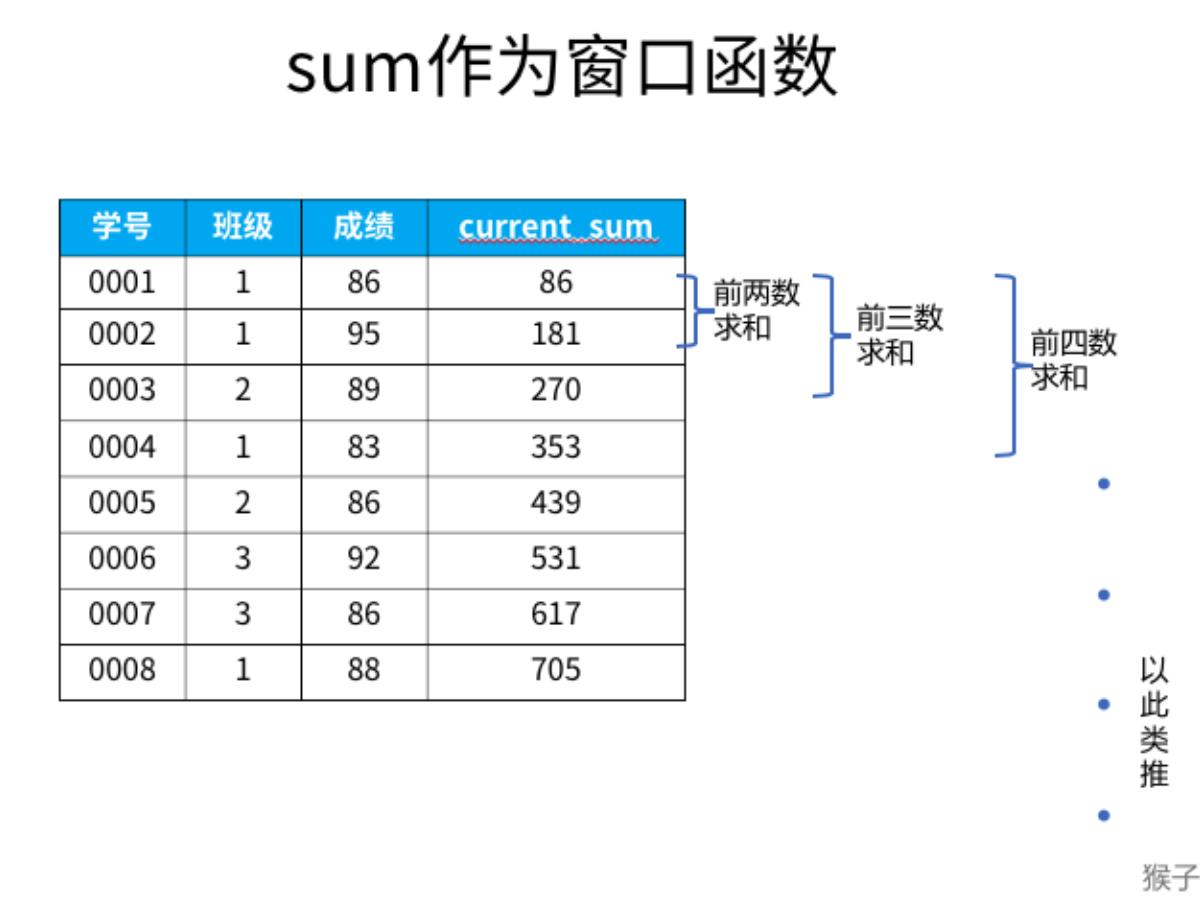
Mysql三范式
第一范式
保证每列的原子性,数据库中所有表的字段值都是不可分解的原子值。第一范式是
对关系模型的基本要求,不满足第一范式就不是关系数据库
第二范式
保证一张表只描述一件事,要求每个行必须可以被唯一区分,非主键与主键有关
联,以下表中学分依赖于课程,年龄和成绩依赖学生,这种表有很多缺点
- 数据冗余 一个课程多个学生修,学分重复。一个学生修多门课,导致年龄和
姓名重复 - 更新异常 如果调整某门课的学分,将导致表中所有这门课的学分都要更新
- 插入异常 如果开设一门新的课,当暂时还没有人修,无法插入完整数据
- 删除异常 如果学生修完一些课,那么这些课就应该删除,但是学分和成绩
也会相应删除
第三范式
保证每列和主键都直接相关,也就是说决定某些字段值的必须是主键 
第二范式与第三范式的区别在于第三范式消除了传递依赖,比如A–B–C,虽然
A和C是有关系的,但是这种关系是通过B来建立的,并不是直接依赖A