
1
参考
《鸟哥的Linux私房菜》 《现代操作系统》
https://blog.csdn.net/SakuraA6/article/details/108810916
计算机概论
概论帮助更好地理解硬件,操作系统与计算机硬件有较大关联性
linux基本介绍
linux应用领域
- 个人桌面
- 服务器
- 嵌入式
Linux是一款免费、开源、安全、高效、稳定的操作系统,处理高并发非
常强,很多企业级项目都部署 到Linux服务器上运行。创始人 Linus Torvalds
Linux主要发行版本,以下这些都是在Linux内核基础上进行修改,相当于二次开发。
- Centos
- Redhat
- Ubuntu
- Suse
- 红旗
主要操作系统
windows ios android mac Linux
Linux和Unix
Unix是由c语言之父用c语言开发出来,Unix出现之后并未开源,后来
Richard Stallman 提出GNU计划,崇尚软件开源,Linux是在Unix
基础上开发出来 应用软件-> shell层 -> 操作系统(Linux) -> 硬件
Linux与windows的比较
windows收费,安全性稍微弱一些,Linux不收费安全性高,windows
不可定制,Linux开源可以定制
VMWare安装
先创建一个虚拟机,然后在虚拟机上安装Centos。VM虚拟机可以虚拟一个
操作系统,首先创建一个虚拟机空间,在空间中安装Centos系统
。 这个系统相当于一系列文件,可以移植到别的主机的VM中 
虚拟机网络连接的三种形式
- 桥连接模式。比如有两台windows主机在同一网段,分别是192.168.0.20
和192.168.0.10,在一台主机上安装Linux系统,那么也在同一个网段地址
也是192.168.0.xx。容易导致ip地址冲突,因为ip地址有限。 - NAT模式。根据以上情况,如果还有一台主机192.168.0.40也在
同一网段安装Linux系统,但是windows系统会出现两个ip地址,另
一个ip是192.168.100.10,此时Linux的ip地址不会占用192.168.0
这个网段而是跟新的ip在一个网段例如192.168.100.20,别的主机无
法找到Linux而Linux可以通过192.168.0.40找到别的主机 - 主机模式。Linux是一个独立的主机不能访问外网
标准分区
- /boot Linux启动时需要一些引导文件默认放在boot分区中 200MB
- swap 当系统内存不足是暂时替代,一般是物理内存的两倍 512MB
- / 剩余空间
终端使用和联网
cd /etc/sysconfig/network-scripts/ 修改配置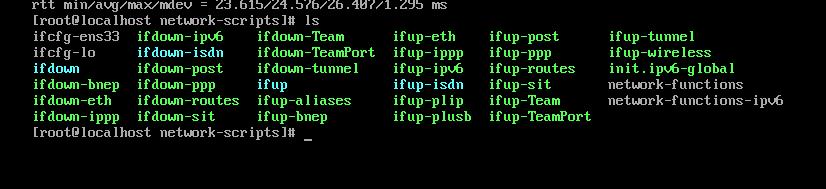
vi ifcfg-ens33 修改配置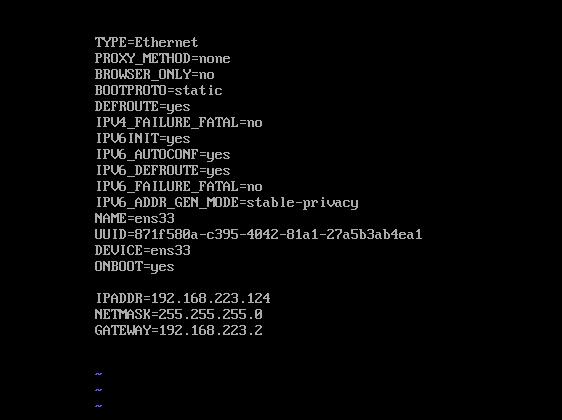
IPADDR前三个数需要与以太网ip前三个相同,编辑中虚拟网络编辑器
查看网关和子网掩码 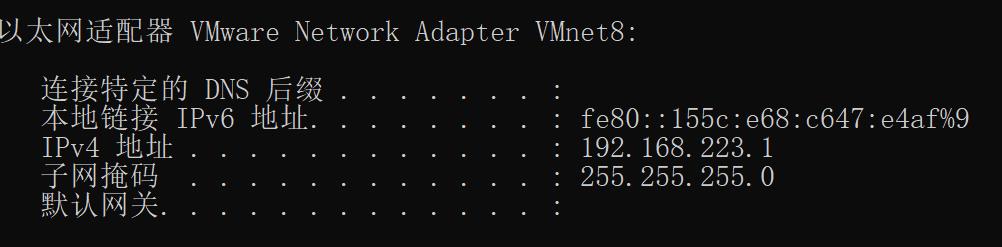
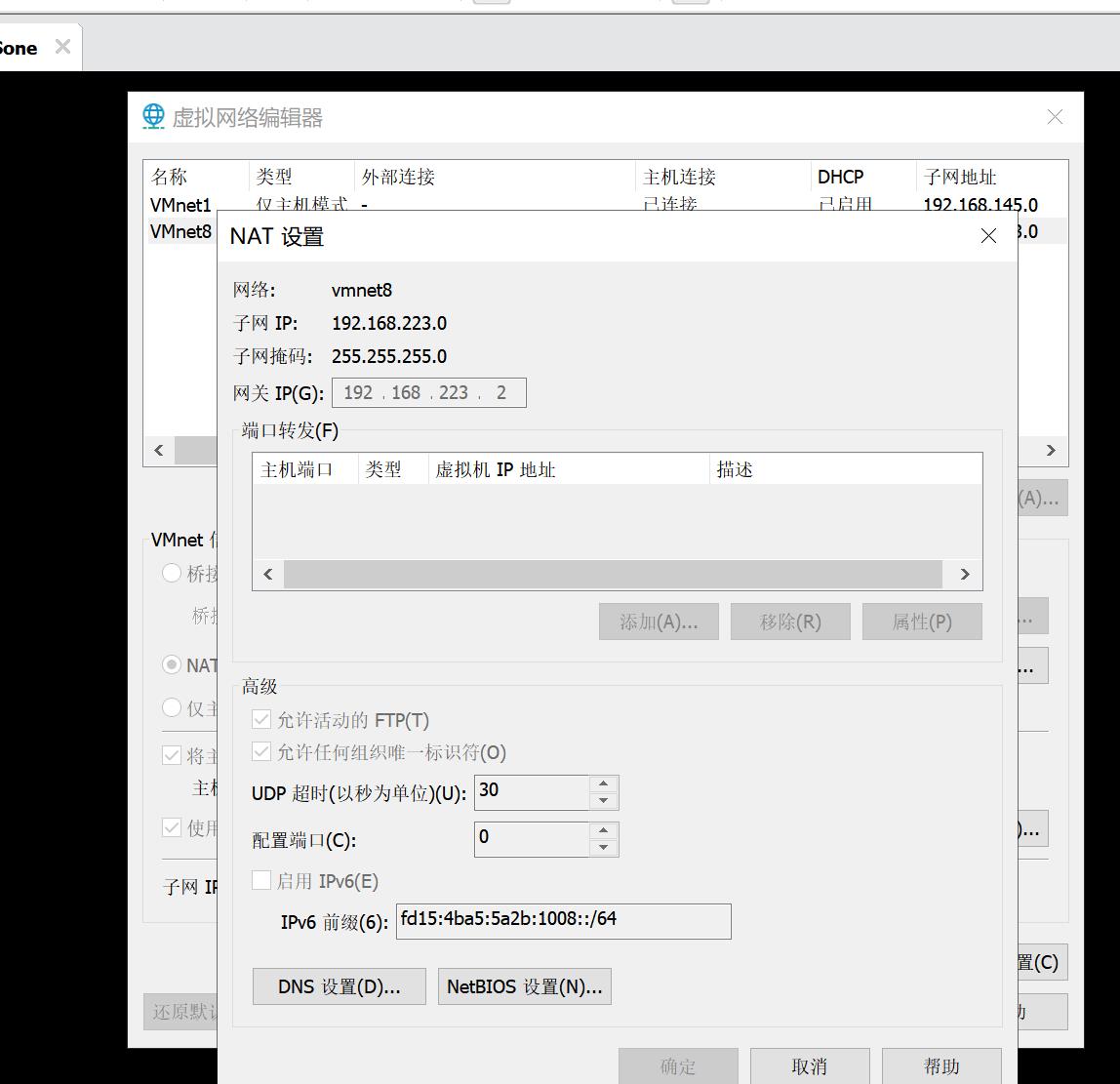
设置DNS
vi /etc/resolv.conf 编辑 resolv.conf文件
nameserver 114.114.114.114 //添加DNS地址
阿里 223.5.5.5 或者 223.6.6.6
谷歌 8.8.8.8
国内移动、电信和联通通用的DNS 114.114.114.114
查看是否能访问外网
输入 service network restart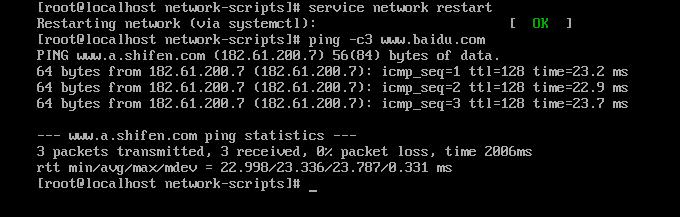
vmtools的安装和使用
安装之后可以直接粘贴命令在windows和centos之间,可以设置两者的共享文件
./vmware-install.pl
文件系统目录结构
Linux的文件系统采用级层式的树状目录结构,在此结构的最上层是唯一根目录 “/“
在Linux世界中一切皆文件,是以文件的形式管理设备,各个目录存放的内容是规划好的
- / 只有一个根目录
- /bin 存放最经常使用的命令
- /home 普通用户的主目录
- /root root用户的文件
- /boot 启动时使用的核心文件
- /dev 所有的硬件以文件的形式存储
- /etc 配置文件
- /user 应用程序和文件
- /media 自动识别的设备例如u盘、光驱会挂载到这个目录下
- /mnt 挂载别的用户系统
- /opt 安装软件所放的目录
- /user/local 软件安装后放的目录
- /var 日志文件
安装gcc
yum -y install gcc gcc-c++ kernel-devel //安装gcc、c++编译器以及内核文件
gcc -v
安装xshell
专门用于远程登录Linux并且可以完美解决中文乱码,xftp可以远程上传下载文件
在centos中查看ip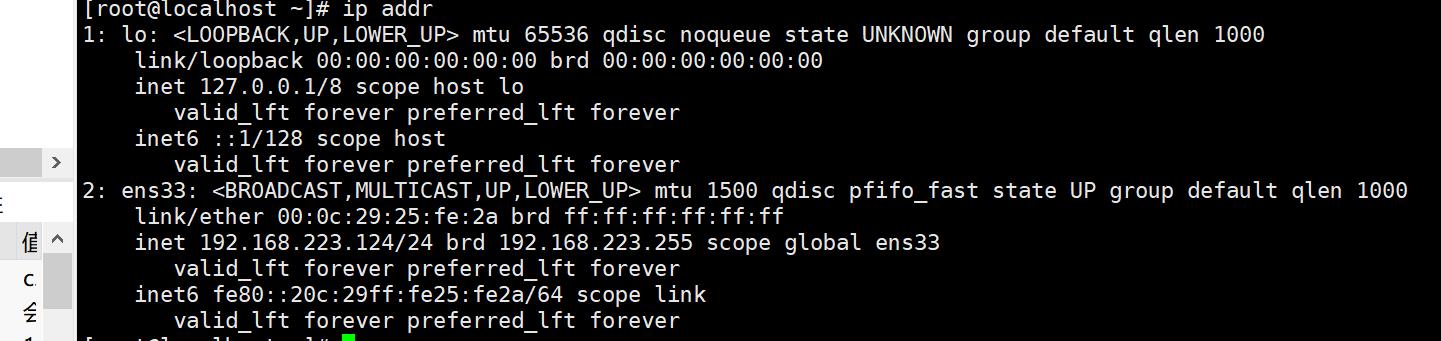
配置虚拟机ip
打开网络中的更改适配器选项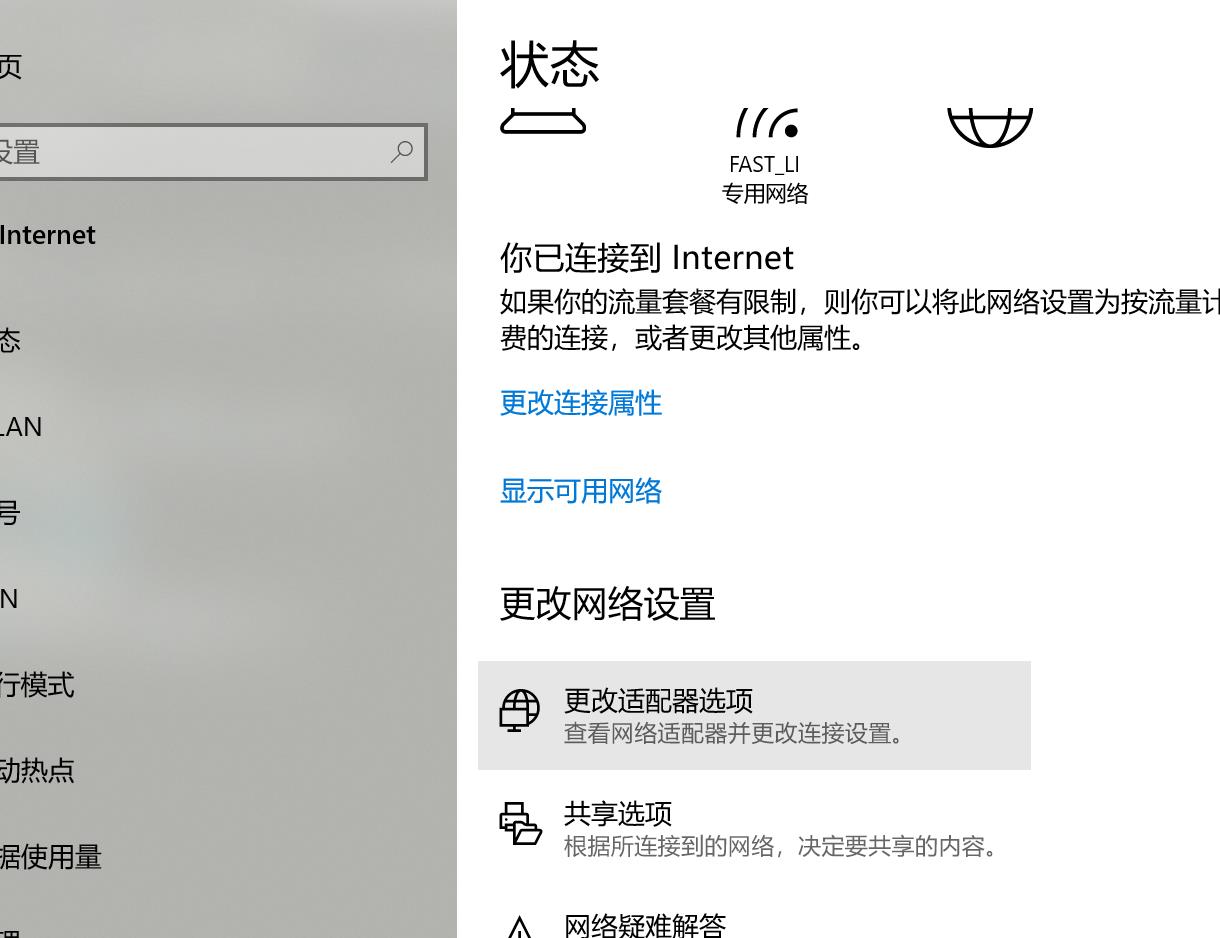
如图进行配置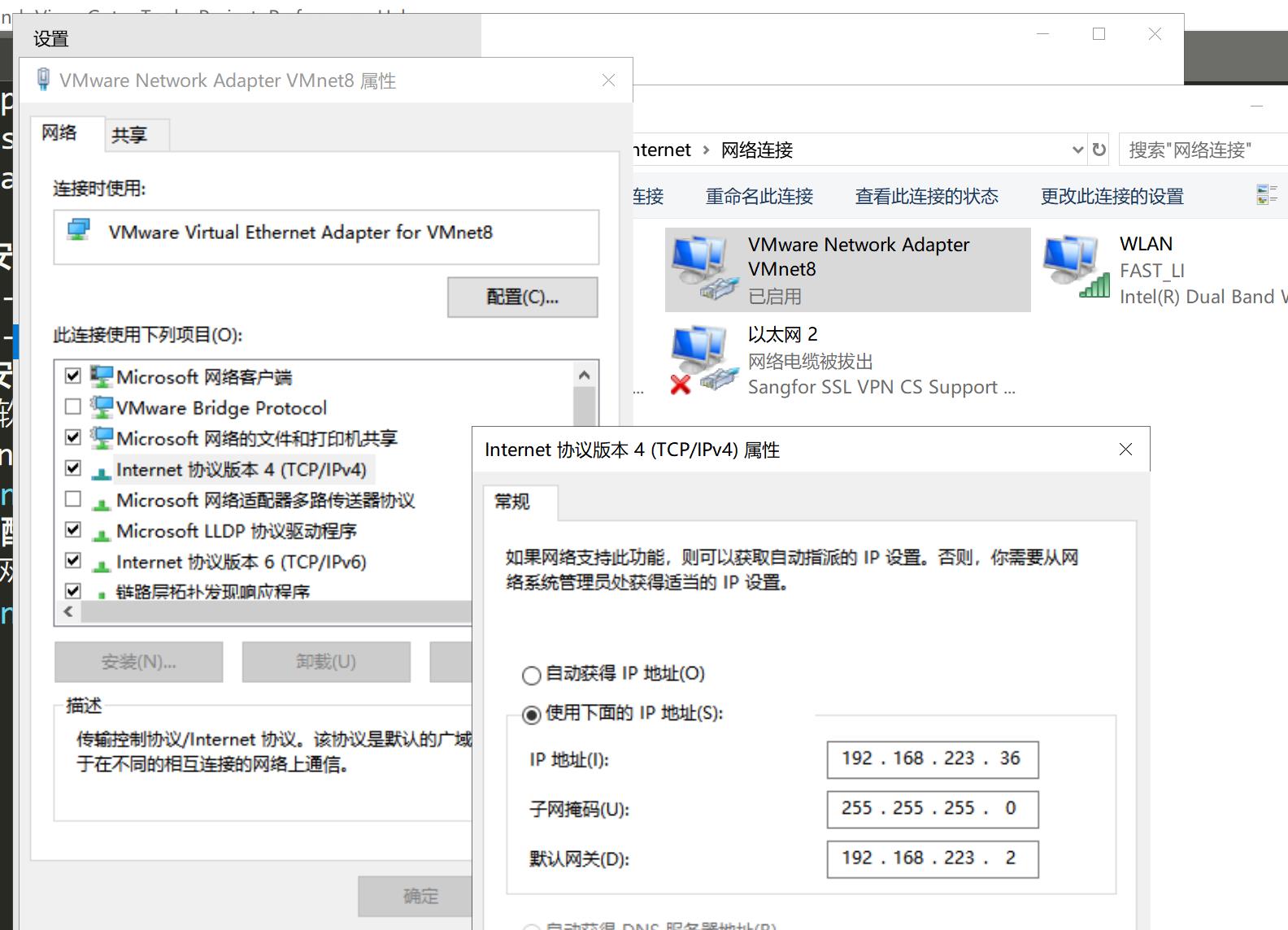
xshell连接centos
打开安装好的xshell,新建会话,在主机的地方输入我们在centos设置好的IP地址,勾选tcp选项
输入用户名和密码完成连接。Linux必须开启sshd服务才可以连接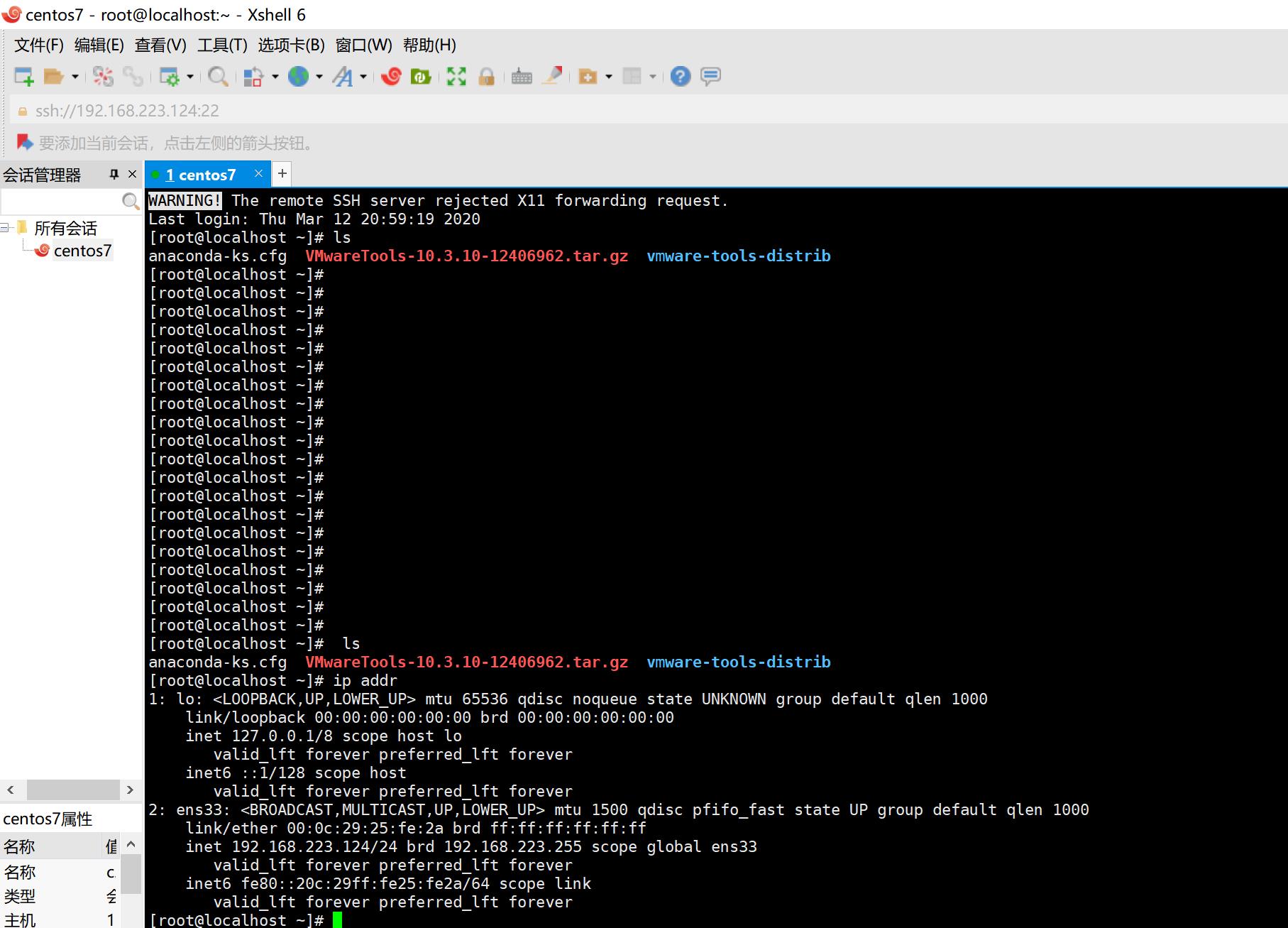
vi和vim
所有的Linux系统都会内建vi文本编辑器,vim是vi的增强版
三种常见模式
- 正常模式
可以使用快捷键 - 插入模式
可以输入内容 - 命令行模式
可以使用指令
使用vim开发Hello.java
输入 vim Hello.java
输入 i 进入插入模式
输入esc 进入命令行模式
输入 :wq 写入并退出。
常用指令
terminal
命令行界面称为终端界面、terminal、console
- ~代表用户的家目录,root的家目录在/root,所以~就代表/root,如果使用用户gaoming
登录时,家目录就是/home/gaoming,root的默认提示符是#,一般用户用$
注销
- exit 离开系统并不是关机,自己的任务结束但是还有任务在进行
执行命令
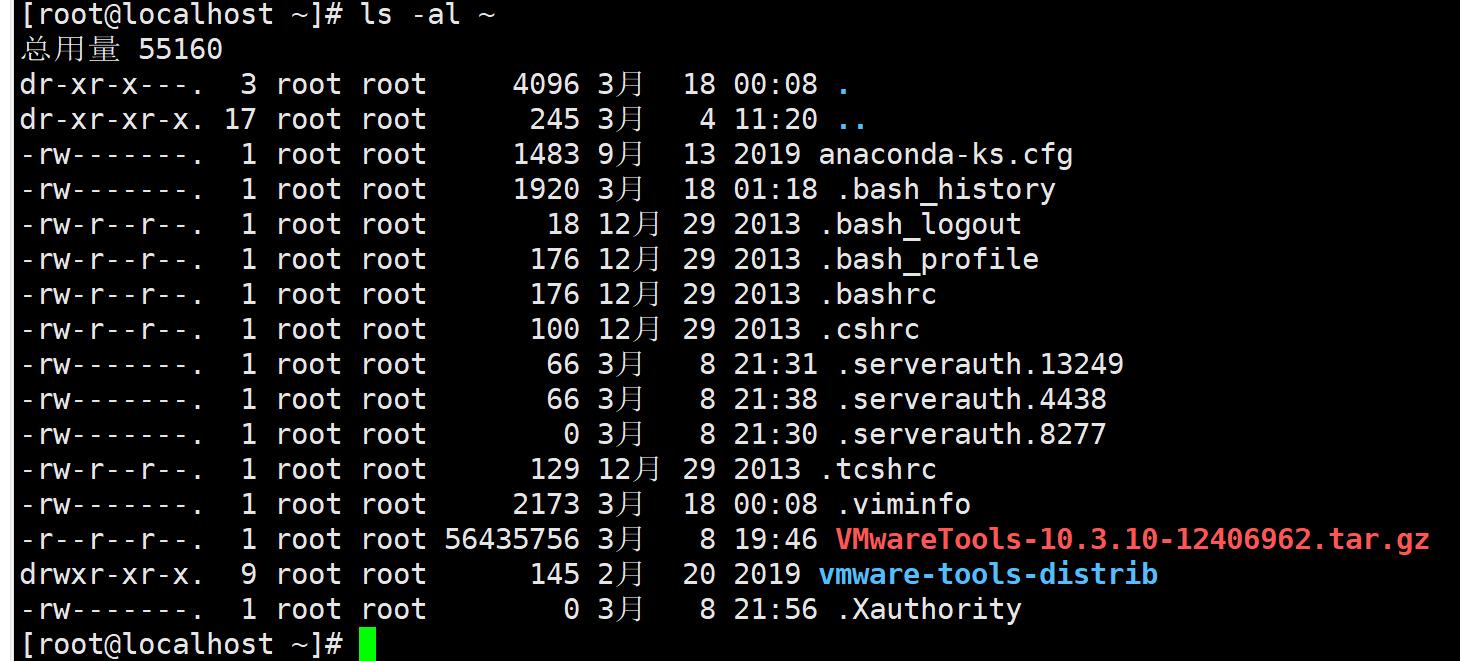
区分大小写,多个空格当一个,换行要使用\
- command [-options] parameter1 parameter2
- ls -al ~ 列出自己家的目录所有隐藏文件与相关文件属性
- ls -a -l ~
基础命令的操作
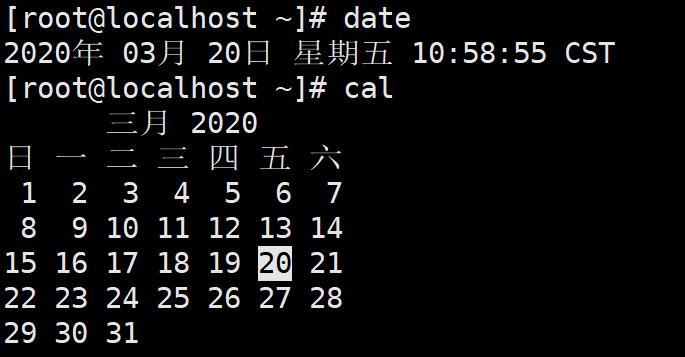
- date 显示日期与时间
- cal 显示日历
重要的几个热键

- TabTab 命令补齐与文件补齐
- 如果在command后面就是命令补齐
- 第二个字段后面就是[选项,参数]补齐
- ctrl-c 中断目前程序
- 错误信息
正确关机
- sync 更新数据
- shutdown -h now
- reboot
用户与用户组
Linux是多人多任务的系统,每个文件都有用户、所属群组及其他人三种身份的个别权限
文件权限
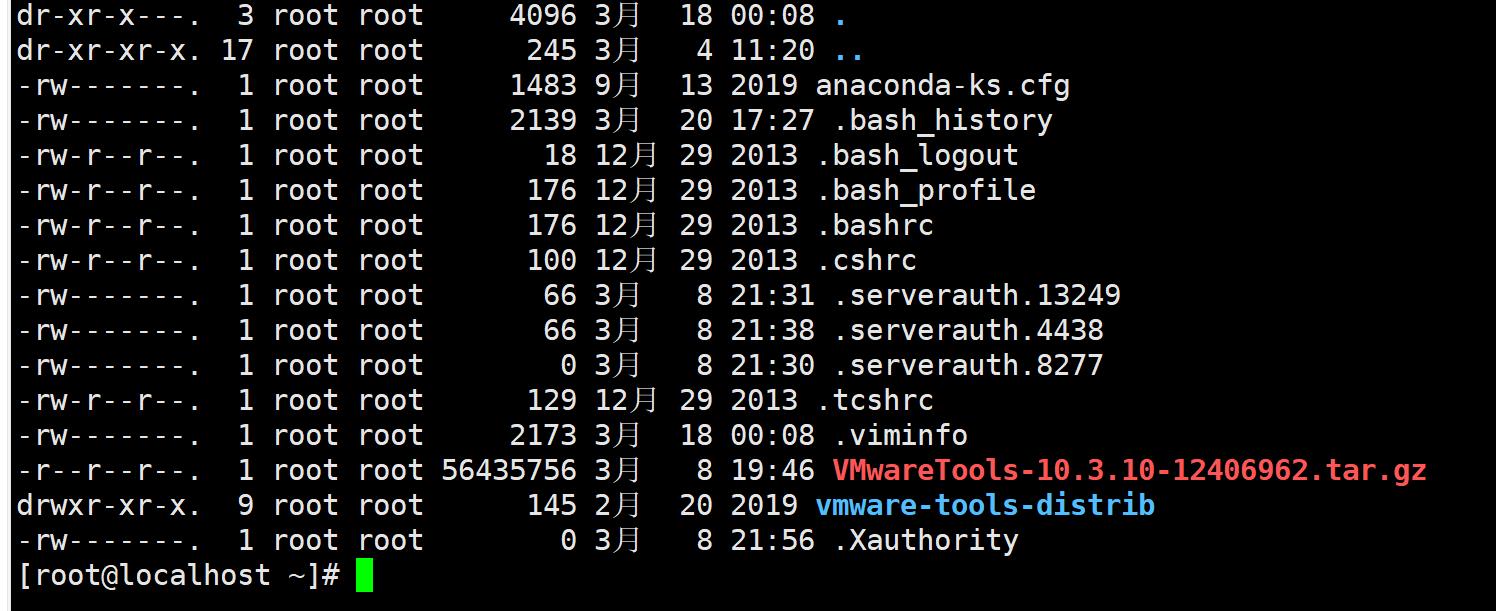
- su 可以切换身份
- ls -al ls显示文件名和相关属性,-al列出所有文件的详细权限和属性
- 文件类型权限 链接数 文件拥有者 文件所属用户组 文件大小 最后修改时间 文件名
- 第一栏有10个字符 第一个字符代表文件类型,d是目录,-是文件,l是链接文件,b是可按
块随机读写的设备,c是设备文件里面的串行端口设备 - 接下来的字符中以三个为一组,且均为rwx的三个参数的组合,r代表可读,w代表可写,x代表
可执行,如果没有权限那么为- - 第一组为文件拥有者可具备的权限,第二组为加入此用户组之账号的权限,第三组为其他人的权限
- 第二栏表示多少文件名链接到此节点
- 第三栏表示文件拥有者账号
- 第四栏表示文件的所属用户组
- 第五栏表示文件的容量大小,默认单位是Bytes
- 第六栏是文件的创建日期或是最近的修改日期
- 第七栏是文件名,如果文件名前有一个.则表示隐藏文件
修改文件属性与权限
- chgrp 修改文件所属用户组
- chown 修改文件拥有者
- chmod 修改文件权限
目录树
绝对路径和相对路径
- 绝对路径 由根目录开始写起的文件名或目录名称 如 /home/dmtsai
- 相对路径 相对于目前路径的文件名写法 如 ./home/ ../../home,也就是不以/开头
- .代表当前的目录,也可以使用 ./
- ..代表上一层目录 也可以使用 ../
目录的相关操作
- . 代表此层目录
- .. 代表上一层目录
- 代表前一个工作目录
- ~ 代表目前使用者身份所在的家目录
- cd 切换目录
- pwd 显示当前目录
- mkdir 建立一个新目录
- rmdir 删除一个空目录
- ls 查看文件或目录
- cp 源文件 目标文件
- rm 删除文件或目录
- mv source destination 将某个文件移动到某个目录下
- basename和dirname 可以判断是文件名还是目录名
- cat 可以查看文件内容
- touch 创建文件
Vim程序编辑器
所有的UNIX-like系统都会内置vi文本编辑器
操作系统引论
操作系统
操作系统是一组控制和管理计算机硬件和软件资源、合理地对各类作业进行
调度(有效性),以及方便用户(方便性)的程序的集合,是计算机硬件
上的第一层软件
shell和GUI
用户接口程序,处于用户态最低层次,都不是操作系统的一部分
- shell是用户与操作系统进行交互的软件,接收用户命令,然后调
用相应的应用程序,基于文本。例如sh csh ksh bash等 - GUI是图形用户界面,基于图标
特级权
为各种操作定义一个安全级别,通过安全级别的高低可以做到集中管理,减少有
限资源的访问和使用冲突。分为0-3级,0级特权级最高,3级特权级最低。每个
级别能够执行的指令是不一样的。例如创建进程要做很多工作,会消耗很多物
理资源。比如分配物理内存,父子进程拷贝信息,拷贝设置页目录页表等等,
这些工作得由特定的进程去做
分时系统和实时系统
- 分时系统 一个系统中多个用户分时地使用同一台计算机,将系统处理
机时间和内存空间按照一定的时间间隔,轮流地切换给各终端用户的程序
使用。系统把CPU时间分成很短的时间片,轮流地分配给多个作业。它的优
点就是对多个用户的多个作业都能保证足够快的响应时间,并且有效提高
了资源的利用率 - 实时系统 在一定时间限制内完成特定功能,并控制所有实时任务协调
一致工作的操作系统,提供及时响应并具备高可靠性。系统对外部输入的
信息,能够在规定的时间内(截止期限)处理完毕并做出反应。实时系统
又分为硬实时系统和软实时系统,硬实时系统要求在规定的时间内必须
完成操作,这是在操作系统设计时保证的,软实时则只要按照任务的优
先级,尽可能快地完成操作即可
处理器
- 保存变量和临时结果的通用寄存器
- 程序计数器 保存将要取出的下一条指令的内存地址
- 堆栈指针 指向内存中当前栈的顶端
- 程序状态字(PSW)寄存器 包含条件码位(由比较指令设置)、CPU优先
级、模式(用户态或内核态),以及各种其他控制位
当在内核态运行时,CPU可以执行指令集中的每一条指令,并且使用硬件的
每种功能,在用户态不能使用有关I/O和内存保护得到所有指令。TRAP指令
把用户态切换到内核态,并启用操作系统
存储器
- 存储器系统的顶层是CPU中的寄存器
- 下一层是高速缓存
- 再下一层就是主存,称为随机访问存储器
- 下一层是磁盘
CPU上下文
CPU寄存器包含指令寄存器(IR)和程序计数器(PC)。他们用来暂存指令,数据
和地址,程序运行的下一条指令地址,这些都是任务运行时的必要环境。因此
也被称作CPU上下文
CPU上下文切换
从一个程序切换到另一个程序
上下文切换就是把前一个任务的CPU上下文保存起来,然后加载新任务的上下
文到这些指令寄存器(IR)和程序寄存器(PC)等寄存器中。这些被保存下来的
上下文会存储在操作系统的内核中,等待任务重新调度执行时再次加载进来
,这样就能保证任务的原来状态不受影响。
CPU的上下文切换又分为进程上下文切换,线程上下文切换以及中断上下文切换
I/O设备
包括两个部分:设备控制器和设备本身。控制器用于接收命令,给操作系统
提供一个接口
前置知识
常用术语概述
PCB 进程控制块(Process Control Block),系统中存放、管理和控制
进程信息的数据结构TCB 线程控制块
FCB 文件控制块
PID 进程ID(Process ID)
PSW 程序状态字寄存器,用于存放PC、IR等的信息
PC 程序计数器,存放下一条指令地址
IR 指令寄存器,存放到当前进行的指令
半双工 半双工和全双工是计算机网络中的概念,意思是通讯同一时间只允许
一方发送数据(对讲机)全双工 通信允许两方向上同时传输数据(电话)
P操作 来自荷兰语proveren,代表wait原语,通常使用P(S)代替wait(S)
V操作 来自荷兰语verhogen,代表原语signal,通常使用V(S)代替signal(S)
用户态 一般的操作系统对执行权限进行分级,分别为用保护态和内核态。
用户态相较于内核态有较低的执行权限,很多操作是不被操作系统允许的,
从而保证操作系统和计算机的安全内核态 内核态相当于一个介于硬件与应用之间的层,可以进行硬件的调
度、使用,可以执行任何cpu指令,也可以引用任何内存地址,包括外围设备
,例如硬盘和网卡,权限等级最高用户态内核态切换 三种情况下,用户态会转换到内核态,系统调用、程序异
常(例如/0,内存资源耗尽等)、来自外围设备的中断中断 中断是操作系统内核程序夺取cpu的唯一途径,或者说用户程序调用内核
代码的唯一途径,因为在一般情况下,操作系统会将cpu使用权交给应用程序
源语操作
进程控制由原语操作实现
- 原语是由若干条指令构成,用于完成一定功能的一个过程
- 原语操作是一种“原子操作”
- 原语操作是OS内核执行基本操作的主要方法
进程组
进程组是一个或多个进程的集合,同一进程组中的各进程接收来自同一终
端的各种信号,每个进程除了有一个进程ID 之外,还属于一个进程组,
对于一个父进程,它的进程组ID就是它本身的PID,那么它的所有子进程
的组进程ID也都是父进程的PID
进程表
参考 https://zhuanlan.zhihu.com/p/56251739
进程(程序)开始运行时,由Linux系统调用自己的系统函数,在内存中开
辟task_struct结构体,又叫进程表。这个结构体的成员项非常多,多达近
300个。task_struct结构体专门用于存放进程在运行过程中,所涉及到的
所有与进程相关的信息,在进程运行结束后,进程表所占用的内存空间,
会被释放,进程表示数组或链表结构
PCB
参考 https://blog.csdn.net/xiuxiuxiuyuan/article/details/79189564
系统利用PCB来控制和管理进程,所以PCB是系统感知进程存在的唯一标志。
进程与PCB是一一对应的,PCB中记录了操作系统所需的,用于描述进程的
当前情况以及控制进程运行的全部信息
- 进程标识符 每个进程都必须有一个唯一的标识符,可以是字符串,也可
以是一个数字 - 进程当前状态 说明进程当前所处的状态。为了管理的方便,系统设计时
会将相同的状态的 进程组成一个队列,如就绪进程队列,等待进程则要根
据等待的事件组成多个等待队列,如等待打印机队列 - 进程优先级 表示获得CPU控制权的优先级大小
- 特征信息 一般分系统进程、用户进程、或者内核进程等
- 程序开始地址 程序开始地址规定该进程的程序以此地址开始执行
- CPU现场保护结构 寄存器值(通用、程序计数器PC、状态PSW,地址包括
栈指针) - 描述虚拟地址空间的信息(如虚拟地址与物理地址之间的映射关系)
文件描述表
open打开文件后,会在进程的task_struct结构体中,创建相应的结构体,
用以存放打开文件的相关信息。对文件进行读写等操作时,会用到这些信息
,这个数据结构就是我们要讲的“文件描述符表” 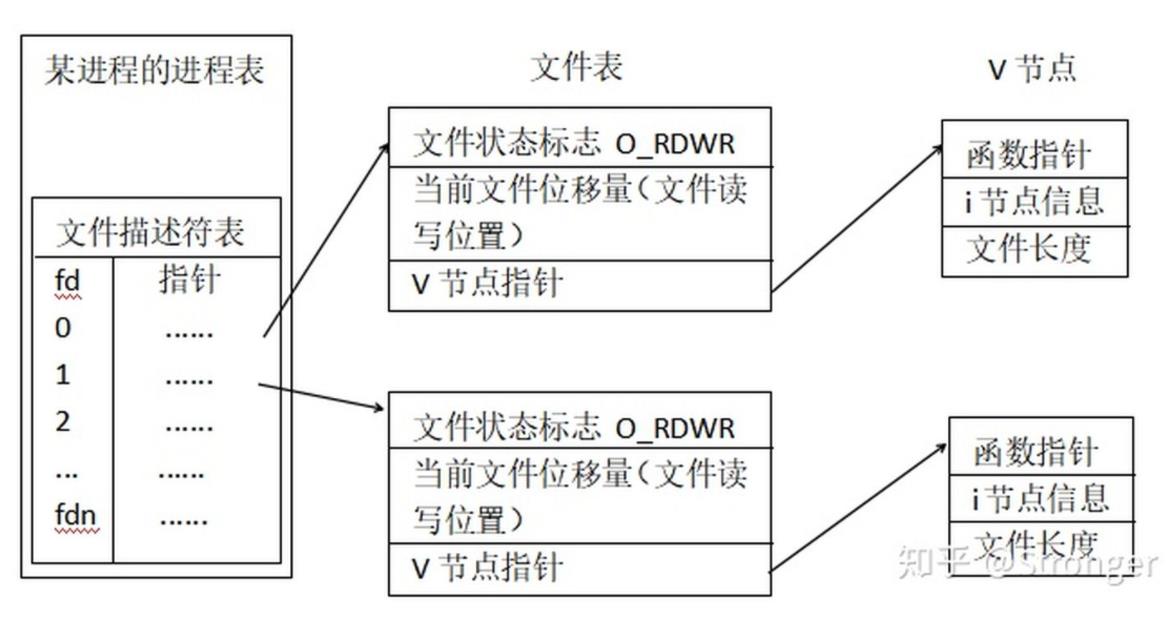
- 文件状态标志 文件状态标志就是open文件时指定的O_RDONLY、
O_WRONLY、O_RDWR等操作权限 - 文件位移量 文件当前读写位置与文件开始位置的距离(字节数)
- 函数指针 在read、write等操作文件时,会根据底层具体情况的不同,
调用不同的函数来实现读写。在V节点里面保存了这些不同函数的函数指针
,方便调用 - 文件长度 记录了文件当前的长度,文件长度是动态更新的
会话
会话:会话(session)是一个或多个进程组的集合,进程调用setsid
函数(原型:pid_t setsid(void) )建立一个会话
竞争条件
两个或多个进程读写某些共享数据,而最后的结果取决于进程运行的精确时
序,称为竞争条件
临界区
把对共享内存进行访问的程序片段称为临界区,要保证高效并发需要满足四
个条件
- 任何两个进程不能同时处于临界区
- 与CPU的速度和数量无关
- 临界区外的进程不得阻塞其他进程
- 进程不能无限期等待
互斥
即以某种手段确保当一个进程在使一个共享变量或文件时,其他进行不能做
同样的操作
- 屏蔽中断
每个进程刚刚进入临界区后立即屏蔽所有中断,并在要离开前打开中断 - 锁变量
一个进行进入临界区时首先测试这把锁,如果锁的值为0则将其设置为1并进
入临界区,如果锁的值为1则等待,但是不能保证别的进程提前调度 - 严格轮换法
忙等待,不符合条件3 - Peterson
一个不需要严格轮换的软件互斥算法 - TSL指令
需要硬件支持的一种方案
共享
- 共享是指系统中的资源可以被多个并发进程共同使用
- 有两种共享方式:互斥共享和同时共享
- 互斥共享的资源称为临界资源,在同一时刻只允许一个进程访问,需要用同
步机制来实现互斥访问
宏内核和微内核
- 宏内核是将操作系统功能作为一个紧密结合的整体放到内核,不管是用户
服务还是内核服务事实上都是内核在统一管理,它们是运行在同一地址空间
中的。由于各模块共享信息,因此有很高的性能,但是很难定位bug,拓展
性比较差,每次需要增加新的功能,都要将新的代码和原来的内核代码重
新编译 - 在微内核中用户服务和内核服务在不同的地址空间中实现。在内核架构中,
用户服务是独立于内核服务的,因此任何用户服务崩溃都不会影响到内核服务
,这就加强了操作系统的健壮性,这是微内核的优势所在。另一点,微内核的
扩展性强,添加一个功能,只需要建立一个新的服务到用户空间当中,而内
核空间不需要任何的修改。因此,微内核可移植性强、安全并且易于扩展。
Linux内核?
- 内核是操作系统的核心部分,它管理着系统的各种资源
- 将应用程序的请求传递给硬件,并充当底层驱动程序,对系统中各种设备
和组件进行寻址
作业和管程
- 作业 用户在一次解题或一个事务处理过程中要求计算机系统所做工作的集
合,它包括用户程序、所需要的数据及控制命令等 - 管程 管程实际上是定义了一个数据结构和在该数据结构上的能为并发进程
所执行的一组操作,这组操作能同步进程和改变管程中的数据
进程与线程
进程
进程是对正在运行程序的一个抽象,一个进程就是一个正在执行程序的实例。
进程是系统进行资源分配的最小单位。在Unix系统中进程由三部分组成,分
别是进程控制块、可执行程序和数据段以及程序的堆栈 
什么是进程?
进程是资源分配的基本单位。由三部分组成:程序、数据及进程控制块(PCB)。
进程控制块描述进程的基本信息和运行状态,所谓的创建进程和撤销进程,
都是指对PCB的操作,PCB中保存程序运行的现场(进程标识、处理机状态
、进程调度、进程控制等信息)
- 优点 内存隔离,单个进程的崩溃不会导致这个系统的崩溃。而且进程方便
测试以及编程简单 - 缺点 创建销毁比较麻烦,进程间数据的共享麻烦,并且消耗的资源比较多
进程的创建
参考 https://blog.csdn.net/kxjrzyk/article/details/81603049
4中事件会导致进程的创建
- 系统初始化
- 正在运行的程序执行创建进程的系统调用
- 用户请求创建一个新进程
- 一个批处理作业的初始化
在UNIX系统中只有一个系统调用可以用来创建新进程: fork。一个进程调用
fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间
。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来
的进程的值不同
1 | int main () |
引用一位网友的话来解释fpid的值为什么在父子进程中不同。其实就相当
于链表,进程形成了链表,父进程的fpid(p 意味point)指向子进程的
进程id,因为子进程没有子进程,所以其fpid为0。
fork出错可能有两种原因:
- 当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN
- 系统内存不足,这时errno的值被设置为ENOMEM
可以通过getpid()函数获得进程标识符,还有一个记录父进程pid的变量,可
以通过getppid()函数获得变量的值。两个进程的变量都是独立的,存在不同
的地址中,不是共用的,fork是把进程当前的情况拷贝一份,执行fork时只
拷贝下一个要执行的代码到新的进程
守护进程
参考 https://www.zhihu.com/question/38609004
守护进程是运行在后台的一种特殊进程,它是独立于控制终端的,并周期性地
执行某些任务,这些进程大部分时候处于休眠状态,只有当有需求的时候才会
唤醒这些进程,比如接收电子邮件的进程、接收Web 访问的进程和处理打印活
动的进程等,UNIX系统有很多守护进程,守护进程程序的名称通常以字母“d”
结尾。
守护进程是个特殊的孤儿进程,这种进程脱离终端,为什么要脱离终端呢?之
所以脱离于终端是为了避免进程被任何终端所产生的信息所打断,其在执行过
程中的信息也不在任何终端上显示。由于在Linux 中,每一个系统与用户进行
交流的界面称为终端,每一个从此终端开始运行的进程都会依附于这个终端
,这个终端就称为这些进程的控制终端,当控制终端被关闭时,相应的进程
都会自动关闭
查看守护进程
ps axj
- a 表示不仅列当前用户的进程,也列出所有其他用户的进程
- x 表示不仅列有控制终端的进程,也列出所有无控制终端的进程
- j 表示列出与作业控制相关的信息
创建守护进程
因为守护进程是脱离终端控制的,所以要造成一种在终端里已经运行完的假象
,把所有的工作都放在子进程中去完成。我们知道,父进程退出后,子进程其
实就是变成了孤儿进程,孤儿进程一般是由1号进程收养,也就是我们所谓的
init进程,也就是说原来的子进程变成了init的子进程,对于守护进程,需
要遵守一些编写规则
- 在后台运行:为避免挂起控制终端,将守护进程放入后台运行。方法亦即
在进程中调用fork 后使父进程终止,子进程则继续在后台运行1
2if ((pid = fork()) != 0) /* parent */
exit(0); - 当前目录更改为根目录:从父进程处继承过来的当前工作目录可能在一个
挂载的文件系统,所以如果守护进程的当前工作目录在一个挂载文件中,那
么该文件系统就不能被卸载
孤儿进程
一个父进程退出,而它的一个或多个子进程还在运行,那么这些子进程将成为
孤儿进程,孤儿进程将被init 进程(进程号为 1)所收养,并由init 进程
对它们完成状态收集工作。孤儿进程由于有init进程循环的wait()回收资源
,因此并没有什么危害
僵尸进程
僵尸进程就是当子进程比父进程先结束,而父进程又没有释放子进程占用的资
源,此时子进程将成为一个僵尸进程,一个子进程的进程描述符在子进程退出
时不会释放
僵尸进程的危害
系统所能使用的进程号是有限的,如果产生大量僵尸进程,将因为没有可用的
进程号而导致系统不能产生新的进程
为什么子进程不直接结束?
因为父进程有时候需要获取到子进程的退出状态,如果是正常退出,可以直接
将其释放,如果是异常退出,又可以根据异常信息进行进一步的相关操作
如何解决僵尸进程?
可以使用wait函数和waitpid函数来处理
- 对于wait函数,父进程调用该函数的时候,如果子进程还没有运行结束,那
么父进程就会阻塞在这里,直到有子进程结束变为僵尸进程后,会获取子进程
的退出信息,并将它销毁返回 - 对于waitpid函数来说,它的作用和wait函数是一样的,只不过多了两个参
数,可以让用户更灵活的去操作,首先第一个参数是一个pid(进程号)
- 当pid > 0时,只等待进程ID等于pid的子进程
- 当pid = -1时,等待任何一个子进程退出
- 当pid = 0时,等待和父进程相同进程组中的任何子进程
- 当pid < -1时,等待一个指定进程组中的任何子进程,这个进程组的ID等于
pid的绝对值
进程的控制
进程控制相关的原语:创建、终止、阻塞、唤醒、切换。也就是说我们通过原语进
行进程控制,原语的执行具有原子性,不允许被中断,原语的实现可以通过“
关中断指令”和“开中断指令”实现
进程的状态
进程有三种状态:运行态,就绪态,阻塞态
- 运行态 该时刻进程实际占用CPU
- 就绪态 可运行,当因为其他进程正在运行而暂时停止,这是系统技术上的
原因引起的,比如没有足够CPU - 阻塞态 除非某种外部事件发生,否则进程不能运行,这是程序自身固有
原因(键入用户命令之前无法执行命令)1
2cat cha1 cha2 cha3 | grep tree
grep准备就绪可以运行,当输入没完成就必须阻塞
切换条件如下
- 运行 -> 阻塞 等待I/O或事件完成
- 运行 -> 就绪 进程的CPU时间片用完
- 就绪 -> 运行 获得了CPU的时间片
- 阻塞 -> 就绪 I/O或事件完成

进程的组织形式
在一个系统中,通常有数十、数百乃至数千个PCB。为了能对他们加以有效的管
理,应该用适当的方式把这些PCB组织起来。进程的组织形式分为两种:链接
式和索引式 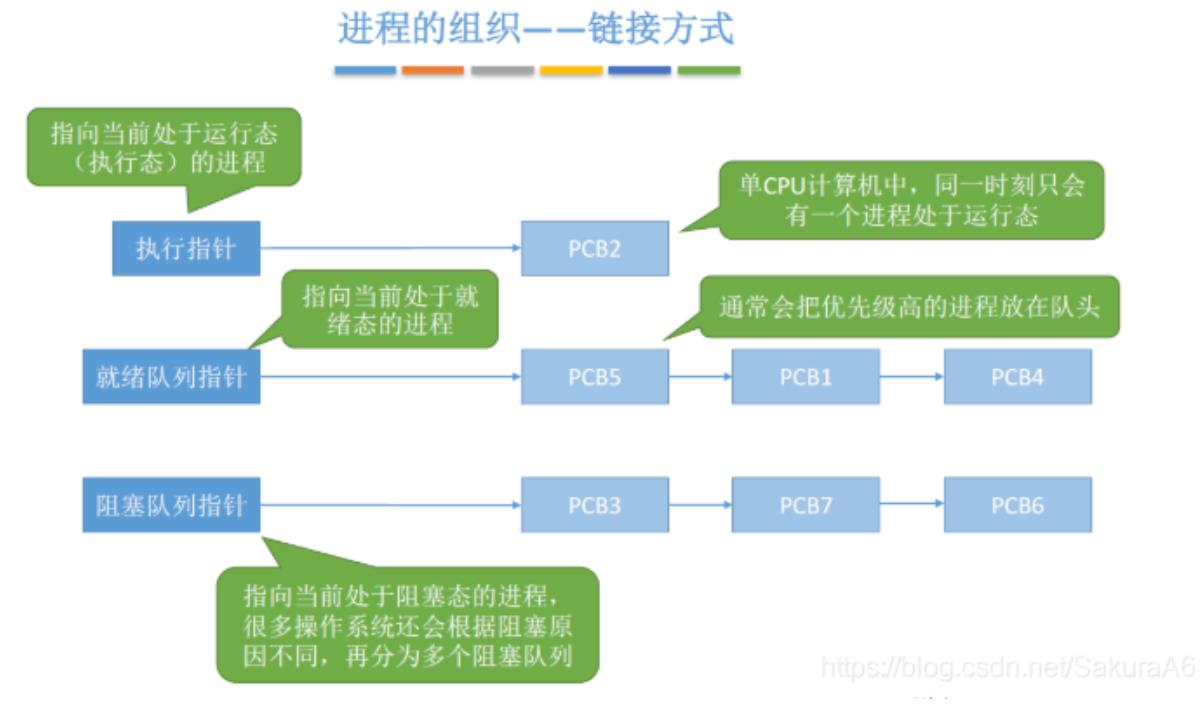
根据进程状态的不同,创建不同的索引表,可以通过指针可以通过索引表指到
个PCB 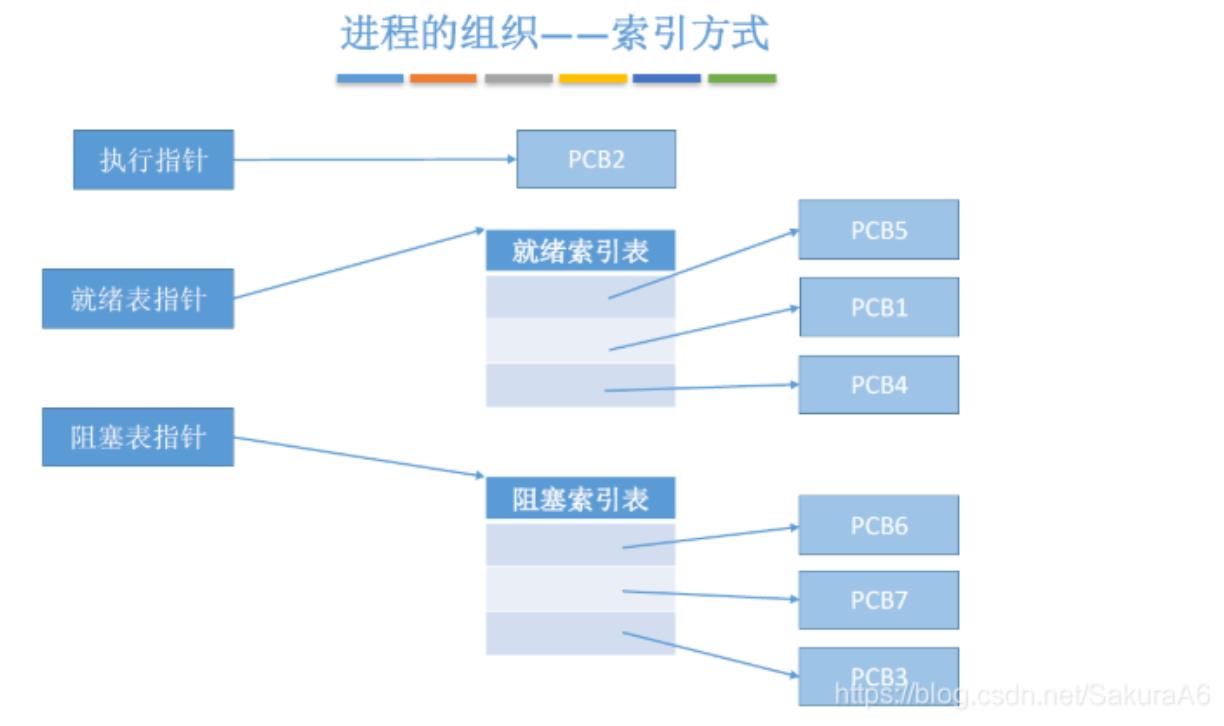
程序的执行
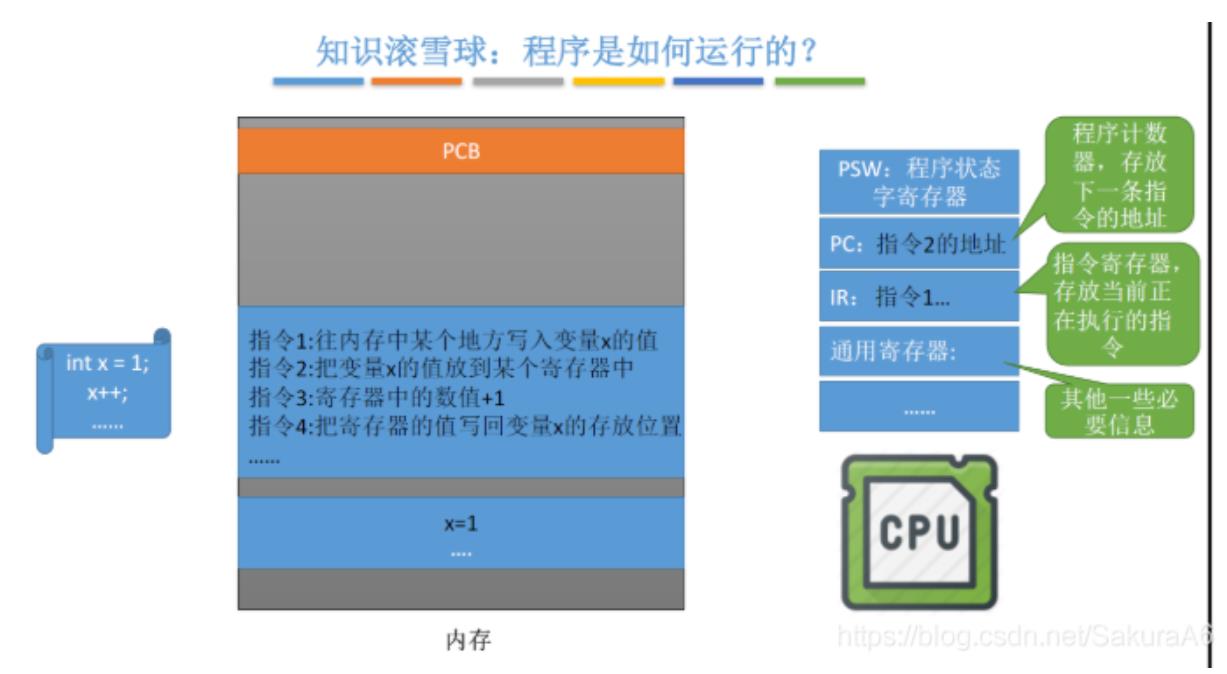
程序的状态字寄存器 PSW用来存放两类信息:一类是体现当前指令执行结果的
各种状态信息,如有无进位(CY位),有无溢出(OV位)等,另一类是存放控
制信息,如允许中断(IF位),跟踪标志(TF位)等 
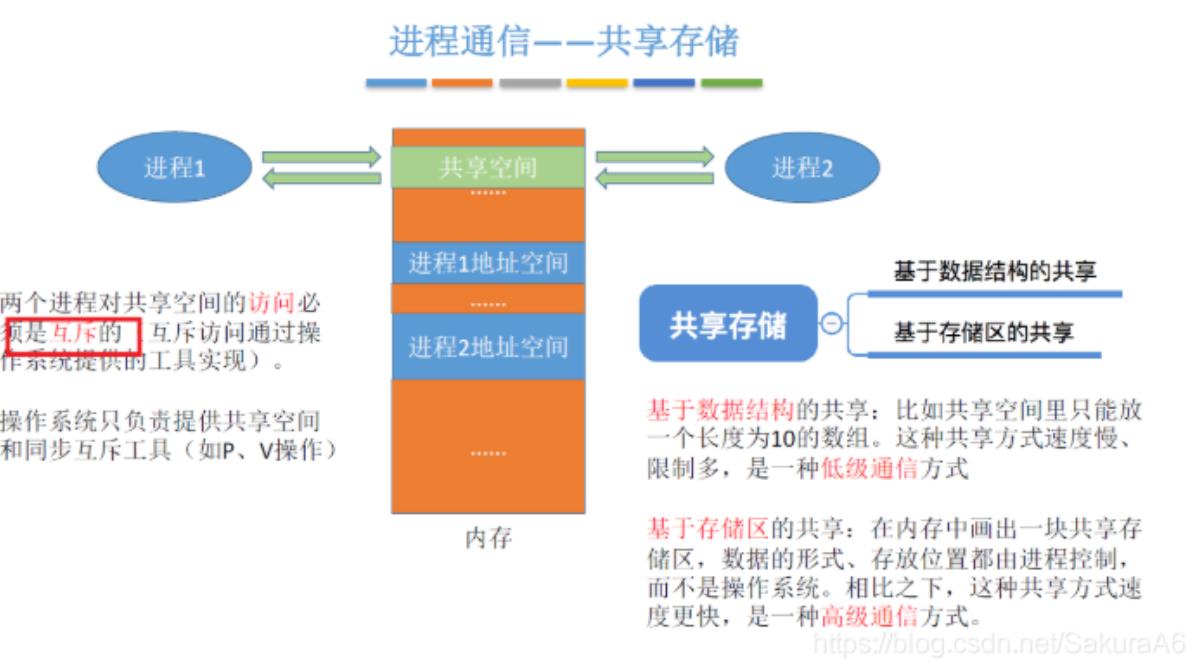
进程通信
进程通信是指进程之间的信息交换。进程是分配系统资源的单位,因此各个进程
拥有的内存地址相互独立,为了保证安全,一个进程不能直接访问另一个进程
的地址空间,为了实现进程通信,操作系统提供了以下方法
- 共享存储
- 信号量
- 消息队列/信箱
- 管道通信
- 套接字(这个在计算机网络有涉及相关知识,可以把套接字理解为一个窗口)
- 信号
睡眠与唤醒
- 信号量
将检查值、修改值以及可能发生的睡眠操作作为一个单一的、不可分割的原子
操作完成,原子性由操作系统保证。在完成前,其他进程不允许访问信号量 - 互斥量
信号量的简化版本,不需要计数能力,只需要两种状态:解锁和加锁。一个二
进制位就可表示它,不过通常用整型 - 管程
是编程语言的组成部分,编译器知道他们的特殊性。任意时刻管程中只有一个
活跃进程。 管程可以看做一个软件模块,它是将共享的变量和对于这些共享
变量的操作封装起来,形成一个具有一定接口的功能模块,进程可以调用管
程来实现进程级别的并发控制。管程具有面向对象编程的特点 - 屏障
通常用于进程组,把他们的执行划分了不同阶段,每个阶段末尾设置一个屏障
,只有所有进程都到达屏障,才能继续运行下一个阶段
共享存储
消息传递
通过原语控制,进程1发送消息到消息缓冲队列或者信箱中,进程2从消息队列或
者信箱中接收消息 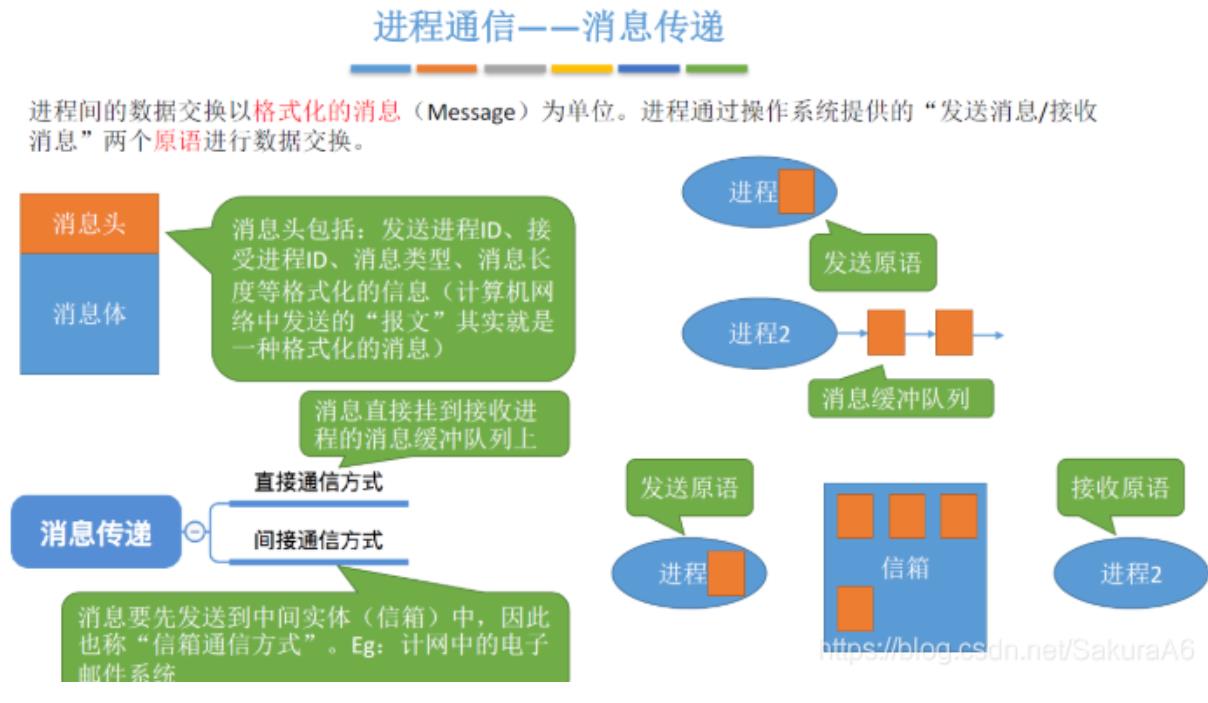
管道通信
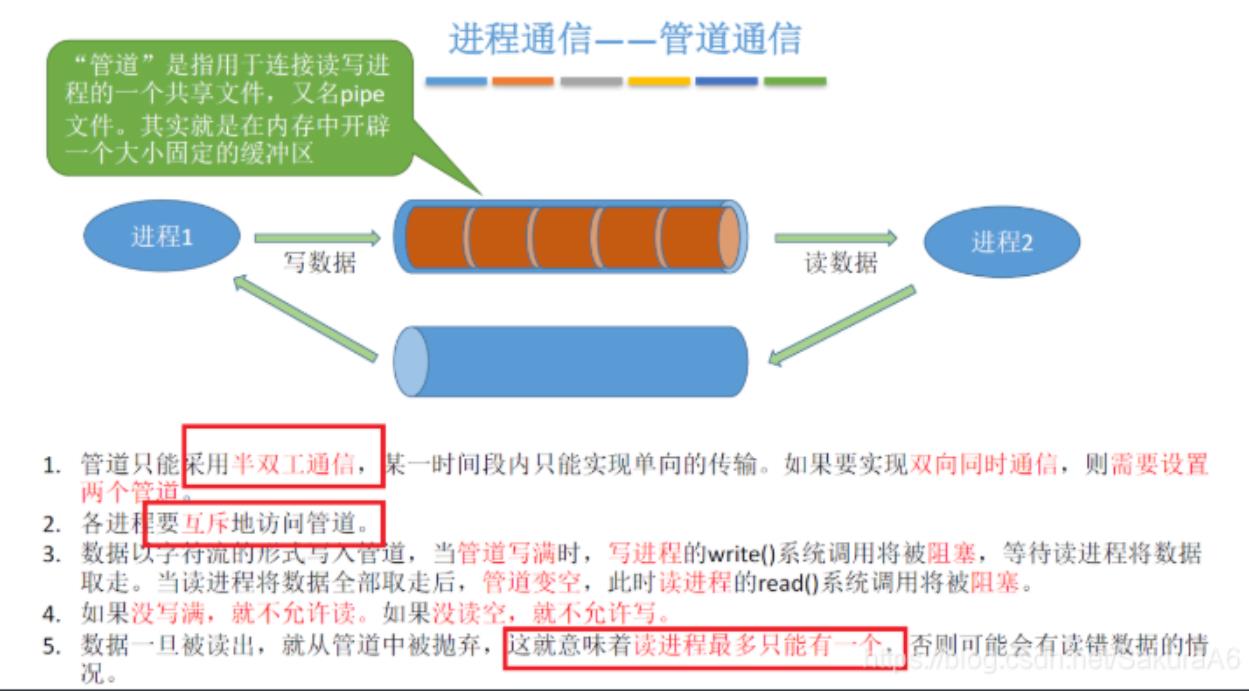
进程的调度
调度的产生是因为系统资源有限,没办法同时处理所有进程,需要特定的规则分
配执行顺序,从而有了调度。操作系统调度层次分为三类:高级调度、中级调度
、低级调度
- 高级调度:从外存的后备作业中挑选一个(多个),建立相应的PCB,获得
竞争处理的权力。后面会讲到的虚拟内存技术出现后,为了提高系统的利用率
和吞吐量,会将暂时等待的进程挂起到外存 - 中级调度:能够决定哪个被挂起的进程重新回到内存中
- 低级调度:从就绪队列中选取一个进程,使其能够被CPU处理
三种调度方式的频率从低到高。进程调度时机:当前运行进程主动放弃(进程中
止、异常、主动请求阻塞),被动放弃(时间片用完、更高优先级的进程进入就绪
队列等)
调度算法
- 先来先服务FCFS:顾名思义,先来的进程先服务,主要从“公平”的角度考
虑(类似于我们生活中排队买东西的例子),非抢占式算法 - 短作业优先SJF:最短的作业/进程优先得到服务,追求最少的平均等待时
间,非抢占式算法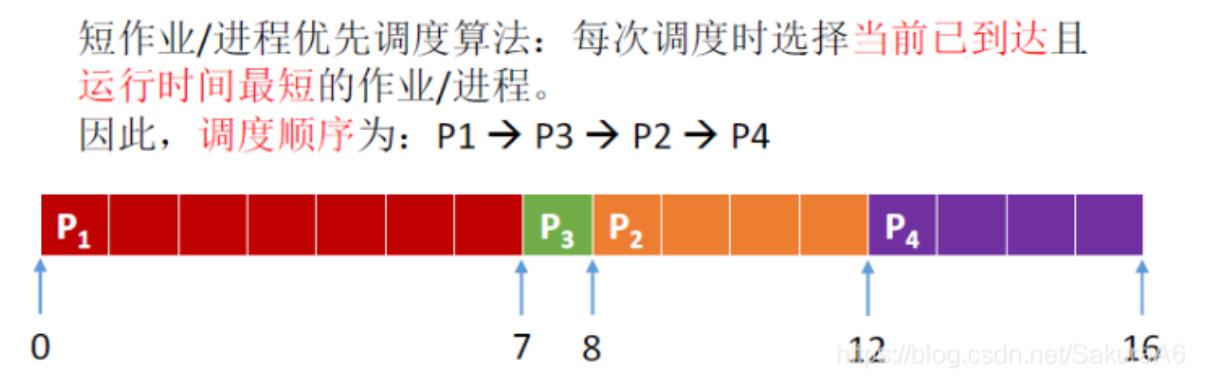
- 最短剩余时间优先算法SRTN:每当有进程加入就绪队列改变时就需要调度
,如果新到达的进程剩余时间比当前运行的进程剩余时间更短,则由新进程
抢占处理机,当前运行进程重新回到就绪队列。是一种抢占式算法
- 高响应比优先HRRN,相应比 = (等待时间+要求服务时间)/要求服务时
间,是一种非抢占式的调度算法,只有当前运行的进程主动放弃CPU时(正
常/异常完成,或主动阻塞),才需要进行调度。以上方法适用于早期的批
到处理系统,适用于交互式系统的调度算法。适用于目前交互式系统的调
度算法,在交互式操作系统中,可以将任务划分为前台任务(鼠标、键盘
等任务)和后台任务,前台任务更关心响应事件,后台任务更关心周转 - 时间片轮转调度算法RR:周期性切换PCB,各个PCB轮流使用CPU
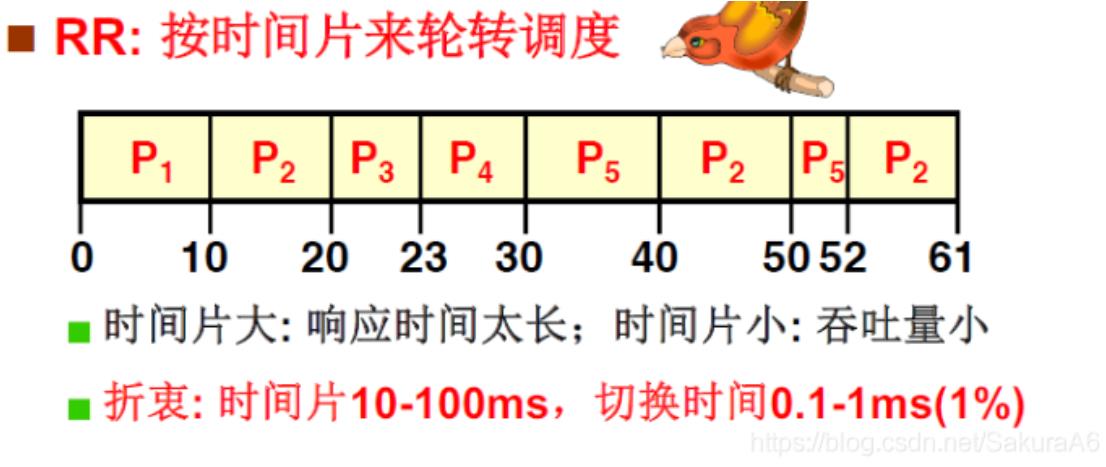
- 最高优先级调度算法 即前台进程优先级高于后台进程,系统进程优先级
会高于用户进程,特点就是不公平,容易产生饥饿
调度算法评价指标
- CPU利用率 = 忙碌的时间/总时间
- 系统吞吐量 = 总共完成了多少道作业/总共花了多少时间 (简单理解就是
一个完成作业的速度指标) - 周转时间= 作业完成时间– 作业提交时间
- 平均周转时间 = 各作业周转时间之和/作业数
- 带权周转时间 = (作业完成时间–作业提交时间)/作业实际运行的时间,
这项指标一定是大于等于1的,越接近一则越好 - 平均带权周转时间 = 各作业带权周转时间之和/作业数
- 等待时间,指进程/作业处于等待处理机状态时间之和
- 响应时间,指从用户提交请求到首次产生响应所用的时间。例如键盘事件
响应时间,鼠标点击响应时间
抢占式和非抢占式
- 抢占式就是说操作系统将正在运行的进程强行暂停,由调度器将CPU分配给
其他就绪进程 - 非抢占式是调度器一旦把处理机分配给某进程后便让它一直运行下去,直
到进程完成或发生进程调度进程调度某事件而阻塞时,才把处理机分配给另
一个进程
进程互斥与同步
进程互斥:当一个进程进入临界区后,另一个进程必须等待。硬件能够实现进
程互斥,有三种方式:利用“开/关中断指令”实现、TSL指令、SWAP指令
信号量机制实现互斥、同步、前驱
- 信号量机制:用户进程可以通过使用操作系统提供的原语对信号量进行操
作,从而很方便的实现进程的互斥、同步、前驱。
一个信号量对应一种资源信,在操作系统中,信号量在源码中其实就对应着
一个变量,代表着某种资源的数量,通过信号量可以实现进程互斥、同步、
前驱 - 进程同步的理解:要让各并发进程按要求有序地推进。若PCB2 的“代码4”
要基于PCB1 的“代码1”和“代码2”的运行结果才能执行,那么我们就必须保
证“代码4”一定是在“代码2”之后才会执行 - 前驱的理解:其实每一对前驱关系都是一个进程同步问题(需要保证一前
一后的操作)
- 信号量保护:共享数据在没有保护的情况下,会出现安全问题,所以需要
锁来进行保护,锁本质也是一个变量,用来保护信号量安全,那锁本身的安
全谁来保护?我们不能在这里套娃对不对,所以锁是一种硬件原子指令,当
要进入临界区时,上锁,离开临界区时解锁
进程的创建过程
- 申请空白PCB
- 分配资源
- 初始化进程PCB
- 将新进程插入就绪队列
相关原语
Pn新进程的外部名,pri优先级,res初始资源,fn执行程序文件名,args是fn
的参数表,add内存区地址,size内存区大小,RQ为就绪队列,EXE是执行态进
程的PCB指针
进程的终止过程
- 进程正常结束 进程变为’stop’,告知父进程
- 异常结束 出现某些错误和故障而迫使进程终止(如越界、非法指令等)
- 外界干预 用户或系统干预,父进程请求或终止
进程的阻塞过程
- 请求系统服务(如请求分配I/O)
- 启动某种操作(如启动I/O)
- 新数据尚未到达(如进程通信)
- 无新工作可做(系统进程)
进程的唤醒?
- 系统请求实现(如获得I/O资源)
- 某种操作完成(如I/O操作完成)
- 新数据已经到达(如其它进程已将数据送达)
- 又有新工作可做(系统进程)
进程的创建
启动系统时会创建若干进程。这些进程分为前台进程和后台进程
- 前台进程 与用户交互
- 后台进程 与特定用户无关,比如接收电子邮件的进程、接收Web访问的
进程和处理打印活动的进程等。这些进程大部分时候处于休眠状态,只有
当有需求的时候才会唤醒这些进程。也称为守护进程
挂起状态
- 挂起状态是一种静止状态,即不能马上投入运行的状态,包括静止就绪状
态和静止阻塞状态 - 处于挂起状态的进程可以存放到外存上保留,而且可以回收这些挂起状态
进程的内存、设备等部分资源 - 处于活动状态的进程 ,可以用挂起原语将其变为挂起状态
- 处于挂起状态(静止状态)的进程,可以用激活原语将其变为活动状态
守护进程
后台进程与特定用户无关,比如接收电子邮件的进程、接收Web 访问的进程
和处理打印活动的进程等。这些进程大部分时候处于休眠状态,只有当有需
求的时候才会唤醒这些进程。也称为守护进程
在UNIX 系统中只有一个系统调用可以用来创建新进程: fork。这个系统调用
会创建一个与调用进程相同的副本。调用fork后,这两个父子进程拥有相同的
内存映像、同样的环境字符串和同样的打开文件。
通常子进程接着执行execve或一个类似的系统调用以修改其内存映像并运行一
个新的程序。之所以安排两步建立进程,是为了在fork之后但在execve之前允
许子进程处理其文件描述符,这样就可以完成对标准输入文件、标准输出文件
和标准错误文件的从定向。内存映像指的是内核在内存中如何存放可执行程序
文件。进程创建以后,父进程和子进程有各自不同的地址空间,但是不可写的
内存区是可以共享的
进程的终止
进程执行完是会终止的
- 正常退出(自愿的)
- 出错退出(自愿的)
- 严重错误(非自愿)
- 被其他进程杀死(非自愿)
当一个进程执行完后会执行一个系统调用,通知操作系统它的工作已经完成,
在UNIX中调用的是exit,在Windows中调用的是ExitProcess。进程终止的
第二个原因是进程发现严重错误,例如用户输入命令
1 | cc foo.c |
要编译这个程序,但是该程序不存在编译器就会推出。进程终止的第三个原因
是进程引起的错误,例如执行了一条非法指令、引用不存在的内存或除数是0
等。在UNIX系统中进程可以通知操作系统,它希望能够自行处理某些类型的
错误,在这类错误中进程会受到信号而中断,而不是在这类错误出现时终止
。第四种进程终止的原因是某个进程执行一个系统调用通知操作系统杀死某
个进程,在UNIX中这个系统调用是kill,在Win32中是TerminateProcess
进程的层次结构
在UNIX中进程和其所有子进程以及后裔组成一个进程组。Windows中没有进程
层次的概念,所有进程地位相同。但注意父进程有一个特别的令牌(句柄),
该句柄可以控制子进程,但是也可以把这个令牌交给别的进程
进程的实现
为了实现进程模型,操作系统维护这一张表格,即进程表。每个进程占用一个
进程表项,该表项包含进程状态的重要信息,包括程序计数器、堆栈指针、内
存分配状况、所打开的文件状态、账号和调度信息,以及其它在进程中由运行
态转换为就绪态或阻塞态时必须保存的信息。下图展示了一个典型系统中的
关键字段。第一列与进程管理有关,其余两列与存储管理和文件管理有关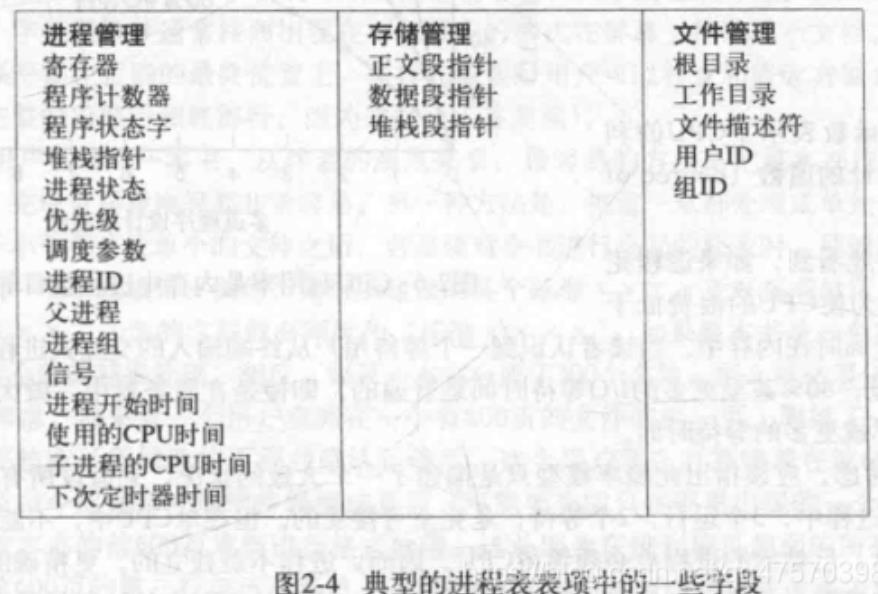
进程的切换都是一次中断,所有的中断都是从保存寄存器开始,对于当前进程
而言,通常是保存在进程表项中,随后会从堆栈中删除有中断硬件机制存入堆
栈的那部分信息,并将堆栈指针指向一个由进程处理程序所使用的临时堆栈,
事实上进程没有独立的寄存器,实质上就是把进程存放在处理器的寄存器中的
中间数据找个地方存起来,从而把处理器的寄存器腾出来让其他进程使用。这
个地方应该是进程的私有堆栈 
多道程序设计模型
采用多道程序设计可以提高CPU的利用率。假设一个进程等待I/O操作的时间
与其停留在内存中的时间比为p,当内存中同时有n个进程时,则所有进程都
在等待I/O的概率是p^n,CPU的利用率如下
1 | CPU利用率=1-p^n |
并发和并行
- 并发是指宏观上在一段时间内能同时运行多个程序,而并行则指同一时刻能
运行多个指令 - 并行需要硬件支持,如多流水线、多核处理器或者分布式计算系统
- 操作系统通过引入进程和线程,使得程序能够并发运行
线程
进程是资源分配的基本单位,线程是调度的基本单位,往往一个进程包含多个
线程。线程并发,系统开销小,不需要切换系统资源,线程的必要性有两点
- 许多应用同时发生多种活动,某些活动随着时间推移会被阻塞,把这些
应用程序分解成可以准并行运行的多个顺序线程,程序设计模型会变简单 - 线程比进程更轻量级,更容易创建和撤销
- 第三个原因涉及性能,若多个线程都是CPU密集型的,那么并不能获得
性能上的增强,但是如果存在大量的计算和大量的I/O处理,那么多个线
程允许这些活动彼此重叠进行,从而加快应用程序执行速度
什么是线程?
线程是调度和执行的基本单位。一个进程中可以有多个线程,它们共享进程资源
。线程自身是不能拥有系统资源的,但是它可以拥有自己的堆、栈、局部变量以
及程序计算器
- 优点 可以提高系统的并行性,数据共享比较方便,切换比较快
- 缺点 没有内存隔离,一个线程的崩溃会导致整个进程的崩溃。编程复杂以
及调试困难
线程有哪两种?
- 用户级线程 线程的处理不通过内核实现,线程的状态信息等全部存放在用户
空间中,内核不能感知用户级线程
- 优点 线程的调度不需要内核直接参与,控制简单
- 缺点 一个用户级线程的阻塞将会引起整个进程的阻塞
- 内核级线程 线程的处理均由内核实现,内核为线程保留TCB,并通过TCB
感知线程
- 优点 当有多个处理机时,一个进程的多个线程可以同时执行
- 缺点 线程在用户态的运行,而线程的调度和管理在内核实现
用户级线程
早期如Unix只支持进程,不支持线程,所以当时的线程是由”线程库”实现的
,用户将进程分为多个线程,放入线程库,但操作系统内核仍然是按照进程
进行处理的,即单线程进程,这种用户级线程是由程序负责管理的,包括进
行切换。这种切换方式开销小,效率高,但下图当一个用户级线程被阻塞后
,整个进程都将会被阻塞,优点是用户级线程包可以在不支持线程的操作
系统上实现 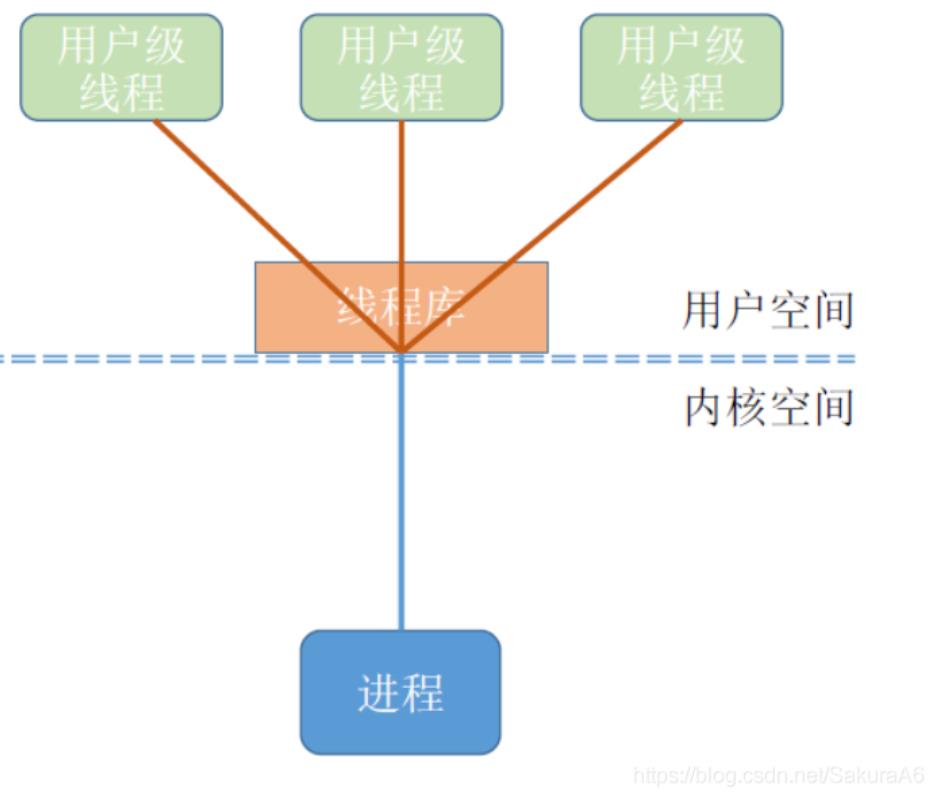
用户级线程的具体内容
在用户空间管理线程时每个进程都有一个线程表,用来跟踪进程中的线程,
记录了每个线程的属性,与进程表类似,由运行时系统管理。当一个线程进
入阻塞状态,那么在线程表中保存寄存器的值,查看表中可运行的就绪线
程,并把新线程的值重新装入机器的寄存器中。如果机器有一条保存所有
寄存器的指令和另一条装入所有寄存器的指令,那么线程切换可以在几
条指令内完成,这样线程切换比陷入内核至少快一个数量级
内核级线程
内核级线程是由操作系统完成调度的。将n个用户级线程映射到m个内核级线
程上(n >= m),优点是克服了多对一模型并发度不高的缺点,又克服了
一对一模型中一个用户进程占用太多内核级线程,开销太大的缺点 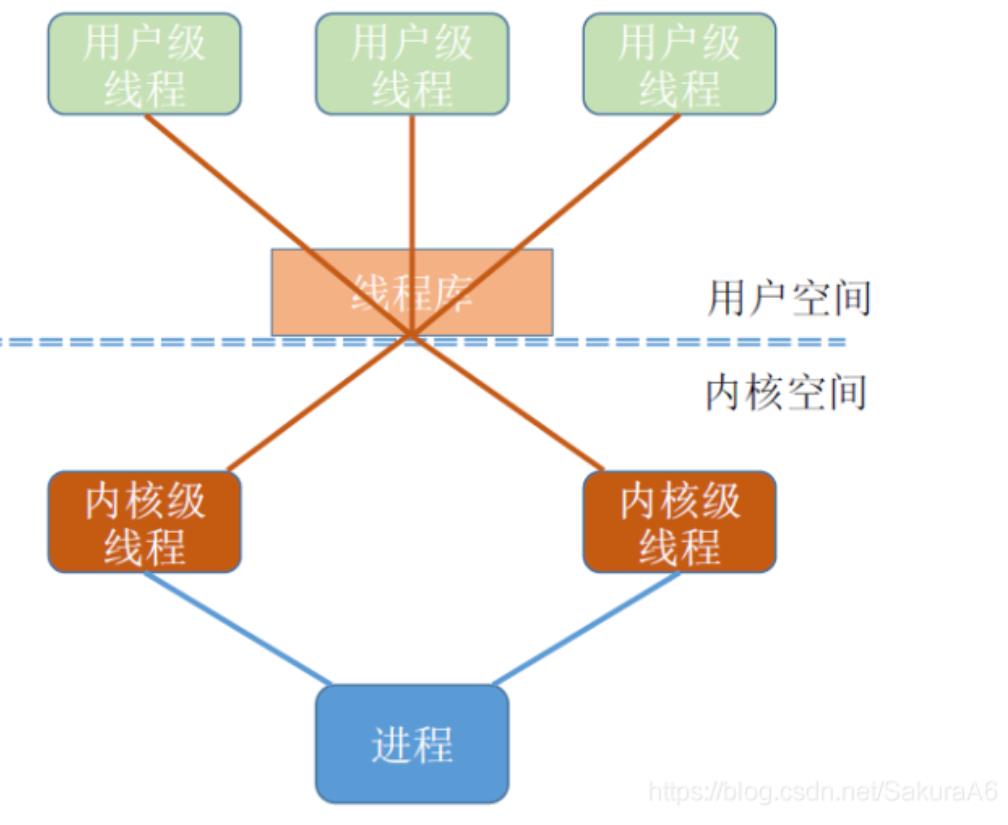
内核级线程的具体内容
不再需要运行时系统,每个进程也没有线程表,在内核中有用来记录所有
线程的线程表
进程和线程的区别
- 资源 进程是资源分配的基本单位,但是线程不拥有资源,线程可以访问
隶属进程的资源 - 线程是独立调度的基本单位,在同一进程中,线程的切换不会引起进程切
换,从一个进程中的线程切换到另一个进程中的线程时,会引起进程切换 - 系统开销 由于创建或撤销进程时,系统都要为之分配或回收资源,如内
存空间、I/O 设备等,所付出的开销远大于创建或撤销线程时的开销。类似
地,在进行进程切换时,涉及当前执行进程 CPU 环境的保存及新调度进
程 CPU 环境的设置,而线程切换时只需保存和设置少量寄存器内容,开
销很小 - 通信方面 线程间可以通过直接读写同一进程中的数据进行通信,但是进
程通信需要借助其他方式
POSIX 线程
参考 https://www.jianshu.com/p/7a17b34e05ee
一般情况下,应用程序通过应用编程接口(API )而不是直接通过系统调用来编程
(即并不需要和内核提供的系统调用来编程),一个API定义了一组应用程序使用
的编程接口,它们可以实现成一个系统调用,也可以通过调用多个系统调用来
实现,而完全不使用任何系统调用也不存在问题。实际上,API 可以在各种不
同的操作系统上实现,给应用程序提供完全相同的接口,而它们本身在这些系
统上的实现却可能迥异 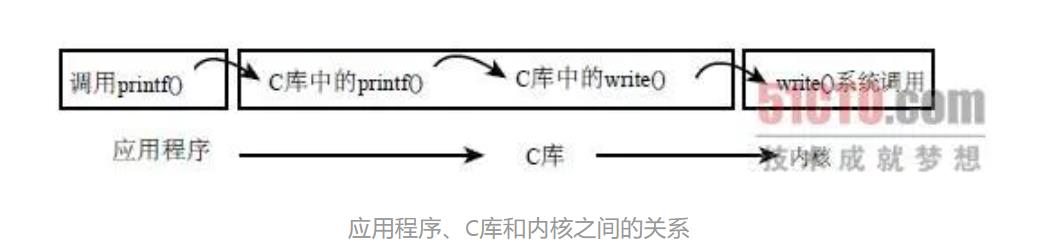
完成同一功能,不同内核提供的系统调用(一个函数)是不同的,例如创建进程
,linux下是fork函数,windows下是creatprocess函数。现在在linux下写一
个程序,用到fork函数,那么这个程序该怎么往windows上移植?我需要把源代
码里的fork通通改成creatprocess,然后重新编译。
POSIX(Protabl Operation System 可移植操作系统规范)就是为了解决这个
问题,linux和windows都要实现基本的posix标准,linux把fork函数封装成
posix_fork(随便说的),windows把creatprocess函数也封装成posix_
fork,都声明在unistd.h里。这样,程序员编写普通应用时候,只用包含
unistd.h,调用posix_fork函数,程序就在源代码级别可移植了。
POSIX标准定义了操作系统应该为应用程序提供的接口标准,是IEEE为要在各种
UNIX操作系统上运行的软件而定义的一系列API标准的总称
pthread
线程包叫做pthread,定义超过60个函数调用,每个pthread线程都有某些特
性,都含有一个标识符,一组寄存器(包括程序计数器)和一组存储在结构
中的属性,这些属性包括堆栈大小、调度参数以及其它线程需要的项目
- pthread_create 创建一个新线程
- pthread_exit 结束调用的线程
- pthread_join 等待一个特定线程退出
- pthread_yield 释放CPU来运行另一个线程
- pthread_attr_init 创建并初始化一个线程的属性结构
- pthread_attr_destroy 删除一个线程的属性结构
posix信号量
参考 https://blog.csdn.net/anonymalias/article/details/9219945
POSIX信号量是属于POSIX标准系统接口定义的实时扩展部分。POSIX信号量有两
种:有名信号量和无名信号量,无名信号量也被称作基于内存的信号量。有名信
号量通过IPC名字进行进程间的同步,而无名信号量如果不是放在进程间的共享
内存区中,是不能用来进行进程间同步的,只能用来进行线程同步。
POSIX信号量有三种操作:
- 创建一个信号量。创建的过程还要求初始化信号量的值
- 等待一个信号量(wait)。该操作会检查信号量的值,如果其值小于或等于0
,那就阻塞,直到该值变成大于0,然后等待进程将信号量的值减1,进程获得
共享资源的访问权限 - 挂出一个信号量(post)。该操作将信号量的值加1,如果有进程阻塞着等待
该信号量,那么其中一个进程将被唤醒。该操作也必须是一个原子操作。该操作
还经常被称为V操作
有名信号量
sem_open用于创建或打开一个信号量,信号量是通过name参数即信号量的名
字来进行标识的
1 |
|
- oflag参数可以为:0,O_CREAT,O_EXCL。如果为0表示打开一个已存在的信
号量,如果为O_CREAT ,表示如果信号量不存在就创建一个信号量,如果存在
则打开被返回。此时mode和value需要指定。如果为O_CREAT | O_EXCL,表示
如果信号量已存在会返回错误 - mode参数用于创建信号量时,表示信号量的权限位,和open函数一样包括
:S_IRUSR,S_IWUSR,S_IRGRP,S_IWGRP,S_IROTH,S_IWOTH - value表示创建信号量时,信号量的初始值
sem_close用于关闭打开的信号量。当一个进程终止时,内核对其上仍然打开的
所有有名信号量自动执行这个操作。调用sem_close关闭信号量并没有把它从系
统中删除它,POSIX有名信号量是随内核持续的。即使当前没有进程打开某个信
号量它的值依然保持。直到内核重新自举或调用sem_unlink()删除该信号量。
sem_unlink用于将有名信号量立刻从系统中删除,但信号量的销毁是在所有进
程都关闭信号量的时候
1 |
|
无名信号量
sem_init()用于无名信号量的初始化。无名信号量在初始化前一定要在内存中
分配一个sem_t信号量类型的对象,这就是无名信号量又称为基于内存的信号
量的原因。sem_init()第一个参数是指向一个已经分配的sem_t变量。第二个
参数pshared 表示该信号量是否由于进程间通步,当pshared = 0,那么表
示该信号量只能用于进程内部的线程间的同步。当pshared != 0,表示该信
号量存放在共享内存区中,使使用它的进程能够访问该共享内存区进行进程
同步。第三个参数value表示信号量的初始值
信号量是什么?
信号量是一种特殊的调度变量,由一个初始值为1的整数 mutex,和一个任
务队列queue 组成,并且提供两个原子操作,wait 和signal,用于管理
- wait(S):等待操作(也叫P操作)首先执行-1操作,如果信号量小于0
,调用block 将任务放入阻塞队列。否则就可以进入临界区 - signal(S):发信号操作(也叫V操作)对信号量执行+1 操作,如果信号
量小于等于0,说明还有其他任务在阻塞队列,就调用wakeup 方法唤醒等
待队列中的一个进程重新开始进入临界区
AND信号量是什么?
将进程运行过程中需要的所有临界资源,一次性地全部分配给进程,也就是
说有多个mutex
- wait 一次性为任务分配所有资源,然后再执行,判断si是否大于等于1
,一旦有任何一个资源没有获取,那么阻塞 - signal 同样在结束之后将所有si 加一,但是这里是取出阻塞队列里面
,与所有si 有关的任务,并且唤醒他们
一般信号量是什么?
AND 信号量描述了竞争多种资源的并发,但是每一种资源数量都为 1。假设任
务需要n 个同种类的资源才能运行,那么就不能简单的通过si≥1 来判断是否
符合任务的要求了。一般信号量机制当信号量si 的值大于某个阈值ti 的时
候,才表示能够分配该资源给任务,否则阻塞
- wait 当信号量 si 的值大于某个阈值 ti 的时候,才表示能够分配该资
源给任务,否则阻塞,所有si 减去di - signal 所有si 加上di,将与si 有关的进程从阻塞队列中唤醒
经典的线程模型
所有的线程有完全一样的地址空间,意味着它们可以共享同样的全局变量,
但每个线程也有自己的程序寄存器、寄存器和堆栈等。对于没有关系的三个
线程可以使用下图左边的结构,如果三个线程实际完成同一个作业并且彼
此积极密切合作可以使用下图右边的结构 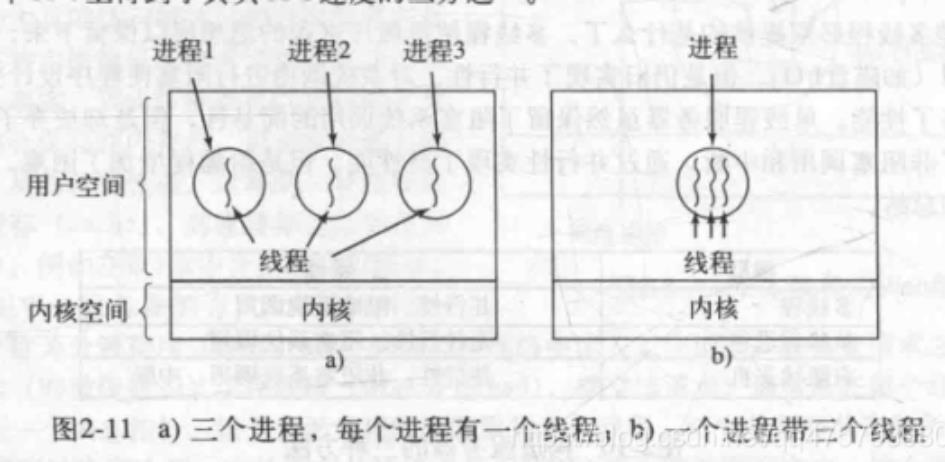
第一列是一个进程中所有线程共享的内容,第二列给出每个线程自己的内容
用户线程优点如下
- 线程切换不用陷入内核,不需要上下文切换,所以线程切换速度很快
- 允许每个进程有自己定制的调度算法
用户线程缺点如下 - 在如何实现阻塞系统调用上实现有困难,而如果采用非阻塞方案,需要
修改原有的操作系统 - 如果一个线程开始允许,那么该进程中其他线程就无法运行,除非第一
个线程放弃CPU,那么线程的调度又是一个问题
进程之间共享和私有的资源?
资源:进程之间私有和共享的资源
- 私有:地址空间、堆、全局变量、栈、寄存器
- 共享:代码段,公共数据,进程目录,进程 ID
线程之间共享和私有的资源?
线程之间私有和共享的资源
- 私有:线程栈,寄存器,程序计数器
- 共享:堆,地址空间,全局变量,静态变量
什么时候适合用多线程和多进程?
- 需要频繁创建销毁的优先使用线程,因为创建和销毁一个进程代价是很
大的 - 线程的切换速度快,所以在需要大量计算,切换频繁时用线程,还有耗时
的操作使用线程可提高应用程序的响应 - 需要更稳定安全时,适合选择进程;需要速度时,选择线程更好
调度
多个进程同时竞争CPU,应该选择哪一个进程执行,这就由操作系统的调度
程序完成,它内部实现了调度算法
进程切换
占用CPU资源的使用者发生了切换。需要保存当前进程在PCB(进程控制块)的
执行上下文(寄存器、数据、打开资源文件等),然后恢复下一个进程上下文
调度
从就绪进程队列中挑一个进程去CPU上执行,何时调度 
- 非抢占式系统:调度算法挑一个去运行,直到该进程阻塞或自动释放CPU
- 抢占式系统:雕塑算法挑一个进程,让其运行固定的最大时间周期,如果时
间到了还在运行,则挂起等待下一次运行,然后切换下一个进程
批处理
- 先来先服务:按照请求CPU的顺序使用CPU
- 最短作业优先:谁的运行时间短,谁先执行,好处是每个作业的平均等待
时间短。如两个进程,A需要运行20分钟,B两分钟,如果先运行A,则B等待20
分钟,总的等待20分钟,平均等待10分钟;如果先运行B,在运行A,则A等
待2分钟,总的等待2分钟,平均等待一分钟 - 最短剩余时间优先:也是抢占式的,每次找到剩余执行最短的程序执行,
给其固定的运行时间,如果到期还没运行完毕,则进入就绪队列等待
交互式
- 轮转调度:也就是大家轮流来,一个进程分配固定时间片,时间到了还没
执行完,则移动到就绪队列队尾,下一个进程接着来 - 优先级调度:优先级高的进程先运行,统一优先级的则按照轮转调度
- 多级队列:举个例子,高优先级的进程先运行一个时间片,然后是次高级
队列每个进程运行2个时间片,然后再次一级运行四个时间片。每个进程运行
一次后,优先级降低一级 - 最短进程优先
- 保证调度
- 彩票调度
- 公平分享调度
实时
- 硬实时调度:在绝对截止时间前完成
- 软实时调度:在某个时间前后完成调度
内存管理
分层存储器体系:高速缓存 内存 磁盘存储。操作系统中管理分层存储器体系
的部分称为存储管理器,它的任务是有效管理内存。
在不使用存储器抽象的情况下也是可以运行多个程序,操作系统只需要把当前
内存中的内存保存到磁盘中,然后把下一个程序读入磁盘即可,只要在某个时
间内存中只有一个程序就不会冲突,这种方式也叫交换。保护键是给内存中每
个块(2KB)一个标识,不同程序的保护键不一样,但是问题在于两个程序都
引用了绝对物理地址,所以需要每个程序都有一套私有的本地地址来进行内
存寻址
地址空间
直接把物理地址暴露给进程会带来几个严重的问题,核心是要保护和重定位
- 很容易破坏操作系统
- 同时运行多个程序很困难
地址空间的概念:是一个进程可以用于寻址的一套内存集合。通俗点讲,就是
每个进程内部有自己的虚拟地址空间0-1023,然后这套虚拟内存空间再映射
到真实物理空间(比如2048 - 3071)。
为了把内部虚拟地址空间转换为真实物理地址,就需要动态重定位,典型的办
法就是给CPU配置两个特殊寄存器,即基址寄存器和界限寄存器。 进程加载到
内存后,基址寄存器用来记录进程物理内存的开始位置,界限寄存器用来保
存程序的长度(也可理解为记录进程物理内存的结束位置)。
使用基址寄存器和界限寄存器重定位的缺点是每次访问内存都需要进行加法和
比较运算。
动态重定位是将每个进程的地址空间映射到物理内存的不同部分,静态重定位
是将进程映射绝对物理地址
交换技术
内存空间是有限的,有两种处理内存超载的通用方法:虚拟内存和交换技术。
交换技术就是把一个进程完整调入内存,使该进程运行一段时间,然后存回
磁盘,空闲进程主要存在磁盘,所以不运行时就不会占用内存。虚拟内存可
以使程序只有一部分调入内存的情况下运行,之后再讲 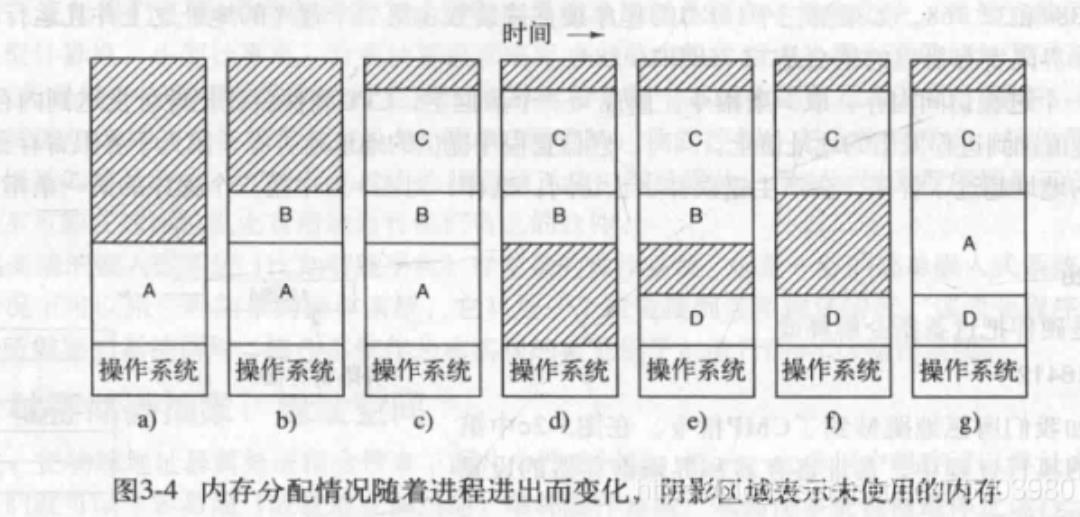
内存紧缩:运行时间长了,进程间的内存就可能有小块未使用的空闲区,把
小块合成一大块连续内存,就叫内存紧缩。但是会耗费大量CPU时间
空闲内存管理
动态分配内存时,操作系统一般有两种方法跟踪内存使用情况:位图和空闲区
链表
- 使用位图的存储管理
使用位图时,内存被划分为几个或几千个字节的单元,即位图中的一位,0表示
空闲,1表示占用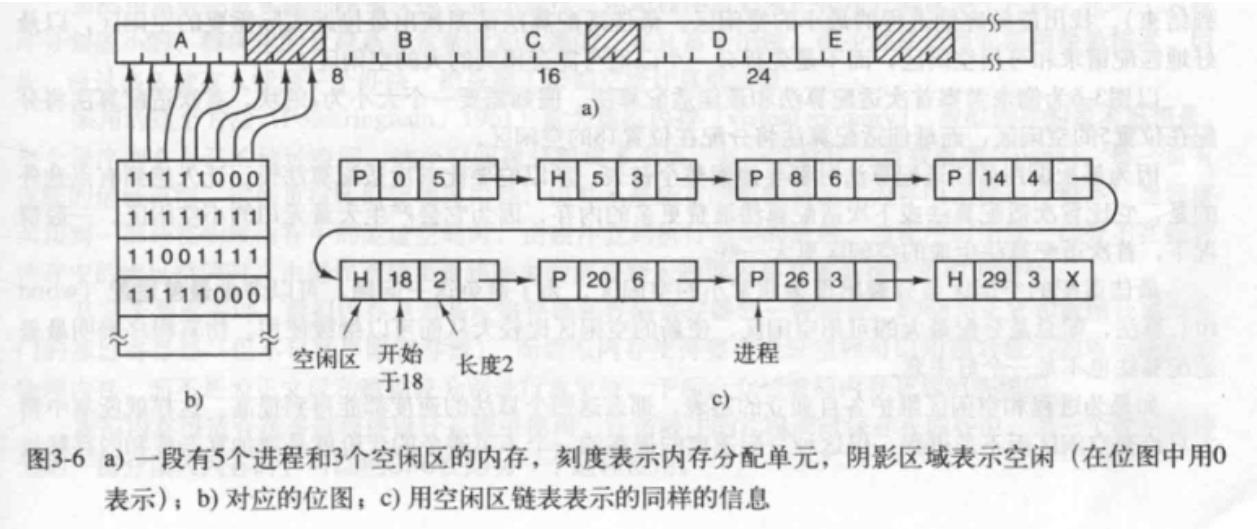
- 使用链表的存储管理
维护一个记录已分配内存段和空闲内存段的链表,如上图所示。内存被划为很
多内存段(每一段不不一定相等),连接起来就是一张链表,一共有四个域
:1.指示标志(P表示空闲,H表示进程占用),2、起始地址,3、长度,4、
指向下一个节点的指针
刚开始时 A,X,B三个进程在运行,内存被划为为三段,如果X终止了,则内存
还是三段,只是X原本占用的这一段就变为了空闲区(如图a)。如果进程X,B
都终止了,则内存变为了两段(如图b),如果A,X,B全部终止,则进程就变
为了一段,如图d.相对应的,在链表中的三个内存节点就变成了一个新的节
点,老的三个节点被删除掉
虚拟内存
为了解决程序大于内存本身的问题,提出了这么一种解决办法:把程序分割成
很多片段,然后程序执行时,先执行第一块,然后执行第二块,这样,运行时
,就只需要把程序的部分加载到内存即可,这个由操作系统动态的在内存和磁
盘上换入换出,这个方法就就演变出了虚拟内存
虚拟内存:每个程序有自己的地址空间,把这个空间分割为多块,每一块称为
一页或页面(page),每一页都有连续的地址范围,执行时这些页映射到物理
内存。当程序执行哪一页时,硬件就去执行,从而不必把所有页都加载到内存
分页
程序自己产生的地址称为虚拟地址,它们构成了虚拟地址空间,虚拟地址通过
内存管理单元映射到物理内存地址上,从而被执行 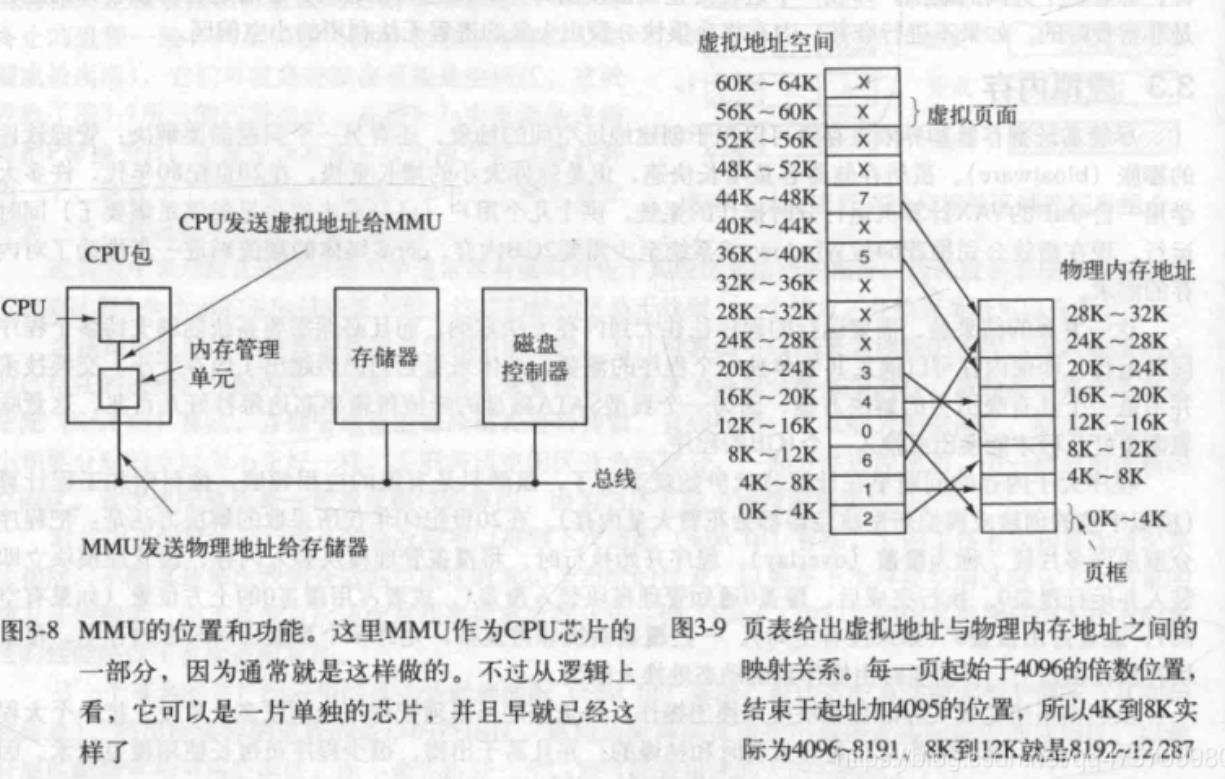
虚拟地址按照固定大小划分为若干个页面, 在物理内存中对应的单元称为页
框(page frame),它们大小通常是一样的。可以理解为每个页框可以容纳
一个页面。 如上图所示, 虚拟页面16个,但是实际物理地址只有8个页框,
RAM和磁盘之间的交换总是以整个页面为单元进行的,很多处理器支持对不
同大小页面的混合使用和匹配,x86-64架构支持4KB 2MB和1GB大小的页面
如果程序要访问一个没有映射到物理页框的页面,就会产生缺页中断或称为
缺页错误,操作系统就会把选择其中一个使用较少的页框,那上面的内容清
除,用来加载需要访问的页面。
上图中只有8个物理页框,于是只有8个虚拟页面被映射到物理内存中,用叉
号表示的其它页面没有被映射,在实际硬件中,用一个在/不在位来记录页
面在内存中的情况,如0表示不在位,1表示在位 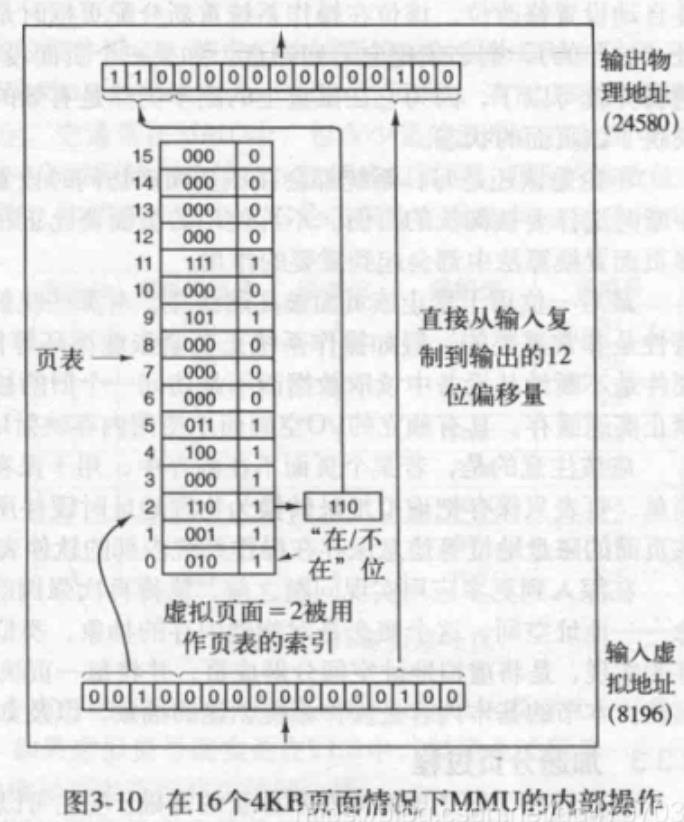
虚拟机地址8196(二进制是0010000000000100)用MMU映射机进行映射,
输入的16位虚拟地址被分为4位页号和12位的偏移量,4位页号可以表示16
个页面,12位偏移量可以为一页内的全部4096个字节编址,在有16个虚拟
页面的情况下,页表由16个虚拟页面组成,假如现在要把一个页面加载进
物理内存,高四位代表在页表的位置,0010换成10进制就是2, 编号2的
这个页面时在位的,并且高三位的物理地址就是110,再加上低12位,就
组成了一个真实的物理地址输出。 这就完成了16位虚拟地址到15位物理
地址的转换
页表
页表的构成:页框号、位,保护位,修改位,访问位,高速缓存禁止位,页
表的目的是把虚拟页面映射成页框
- 保护位:指一个页允许什么类型的访问,读、写、可读写
- 修改位:是否有修改过,修改过,则则需要先写入磁盘保存才能丢弃,
如果没修改过,更换其他页面时,就可以直接丢弃了 - 访问位:是否正在访问、包裹读、写
- 高速缓存禁止位:禁止该页面被高速缓存
虚拟内存本质是用来创造一个新的抽象概念–地址空间。虚拟内存的实现,
是将虚拟地址空间分解成页,并将每一页映射到物理内存的某个页框或者
暂时解除映射
加速分页过程
分页时需要考虑两个问题
- 虚拟地址到物理地址的映射必须非常快
- 如果虚拟地址空间很大,页表也会很大
针对大内存的页表
有多级页表、倒排页表等,方便快速查找寻址
页面置换算法
在发送缺页中断时,需要选择一个页面,将其换出内存,如果每次都选择
不常使用的页面会提升系统性能,如果一个频繁使用的页面被置换出去会
带来不必要的开销,接下来有几种置换算法 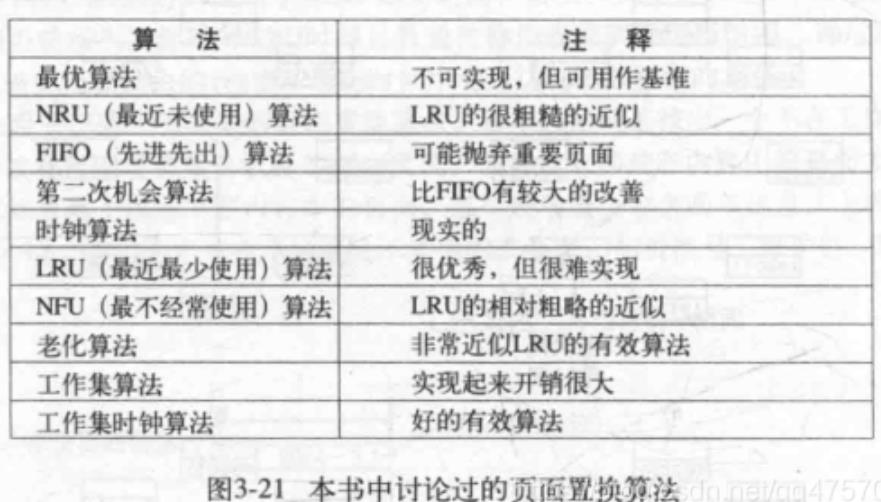
最优页面置换算法
注意该算法是不可实现的,每个页面都可以在用到该页面首次被访问前所要
执行的指令数作为标记,最优页面置换算法规定应该置换标记最大的页面,
但是操作系统无法知道各个页面下一次将在什么时候被访问
最近未使用页面置换算法
系统为每个页面设置两个状态位,可以将页面分为四类
- 没有被访问,没有被修改
- 没有被访问,已被修改
- 已被访问,没有被修改
- 已被访问,已被修改
NRU算法随机从类编号最小的非空类中挑选一个页面淘汰
先进先出页面置换算法
操作系统维护一个所有当前在内存中的页面的链表,最新加入的页面放在表
尾,最早进入的页面放在表头,当发生缺页中断时淘汰表头的页面并把新调
入的页面放在表尾,这就是FIFO算法
第二次机会页面置换算法
对FIFO算法进行修改,检查最老的页面的R位,如果R位是0那么这个页面既
老也没有被使用,可以立刻置换,如果是1就将R位清0,并把该页面放到链
表尾端
时钟页面置换算法
第二次机会算法的缺点就是经常要在链表中移动页面,降低了效率又不是很
有必要,一个更好的办法是把所有的页面都保存在一个类似钟面的环形链表
,一个表针指向最老的页面。当发生缺页中断时,算法首先检查表针执行的
页面,如果R位是0就淘汰该页面,并把新页面插入这个位置,表针前移一
个位置,如果R是1就清除R位并发表针前移一个位置继续判断 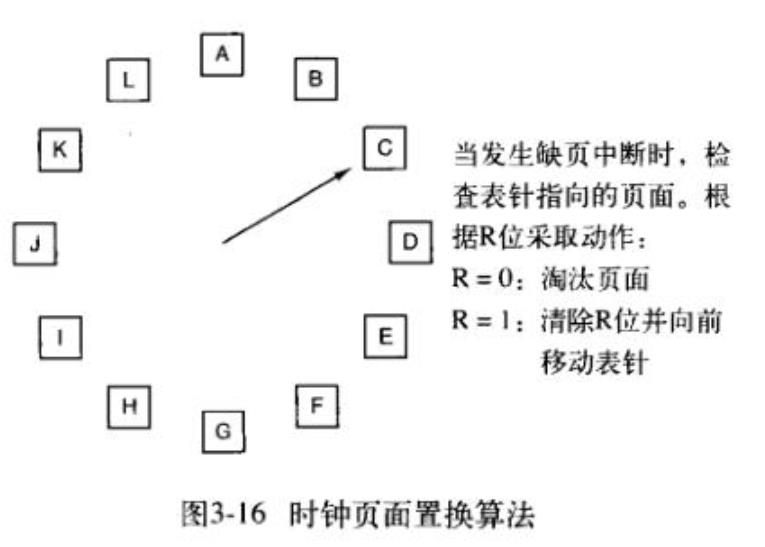
最近最少使用页面置换算法
在缺页中断发生时,置换未使用时间最长的页面,这个策略称为LRU页面置
换算法,为了实现LRU需要在内存中维护一个所有页面的链表,最近最多使
用的页面在表头,最近最少使用的页面在表尾
文件系统

磁盘调度算法
参考 https://blog.csdn.net/sinat_37903468/article/details/108469482
死锁
参考 https://www.cnblogs.com/wkfvawl/p/11598647.html#navigator
指如果一个进程集合中的每个进程都在等待只能由该进程集合中的其他进程
才能引发的事件,那么该进程集合就是死锁
资源
把需要排他性使用的对象称为资源,能够获得以及释放。资源分为两类,可
抢占和不可抢占的,可抢占资源可以从拥有它的进程中抢占而不会产生任
何副作用,不可抢占资源是指在不引起相关的计算失败的情况下,无法把
它从占有它的进程中抢过来
资源死锁的条件
产生死锁有四个必要条件
- 互斥条件 每个资源要么已经分配给一个进程,要么就是可用的
- 占有和等待条件 已经得到某个资源的进程可以再请求新的资源
- 不可抢占条件 已经分配给一个进程的资源不能强制性被抢占,它只能被
占有它的进程显示地释放 - 环路等待条件 死锁发生时,系统中一定有由两个或以上的进程组成的一
条环路,该环路中的每个进程都在等待下一个进程所占有的资源
生产者消费者问题
生产者负责向缓冲区写入数据,而消费者负责从缓冲区取走数据。
于是需要三个信号量。生产者私有信号量empty 保证时刻有空位,消费者私
有信号量full 保证时刻有数据,公共信号量mutex 用于保证任意n 个任
务有且仅有一个在访问缓冲区
生产者
1 | wait(empty) |
消费者
1 | wait(full) |
read和write
- int open(const char *path, int flags,…,/* mode_t mode */);
成功则返回文件标识符;出错返回-1 - ssize_t read(int fd,void *buf,size_t nbytes);
read()会把参数fd所指的文件传送count 个字节到buf 指针所指的内存中,
成功返回读到的字节数,若已到文件尾,返回0,出错返回-1 - ssize_t write(int fd,const void *buf,size_t nbytes);
write()会把参数buf所指的内存写入count个字节到参数放到所指的文件内,
成功返回已写的字节数,出错返回-1
pipe函数
参考 https://blog.csdn.net/judgejames/article/details/84256340
pipe 函数可用于创建一个管道,以实现进程间的通信
1 |
|
该函数成功时返回0,并将一对打开的文件描述符值填入fd参数指向的数组。失败
时返回-1并设置errno。通过pipe函数创建的这两个文件描述符fd[0] 和fd[1]
分别构成管道的两端,往 fd[1] 写入的数据可以从 fd[0] 读出。并且 fd[1]
一端只能进行写操作,fd[0]一端只能进行读操作,不能反过来使用。要实现双
向数据传输,可以使用两个管道。
默认情况下,这一对文件描述符都是阻塞的。如果我们用read 系统调用来读取一
个空的管道,则read将被阻塞,直到管道内有数据可读,如果我们用write系统
调用往一个满的管道中写数据,则write也将被阻塞,直到管道有足够的空闲空
间可用(read 读取数据后管道中将清除读走的数据)。用户可自行将 fd[0] 和
fd[1] 设置为非阻塞的。
如果管道的写端文件描述符fd[1] 的引用计数减少至0,即没有任何进程需要往
管道中写入数据,则对该管道的读端文件描述符fd[0] 的read 操作将返回0,
(管道内不存在数据的情况),即读到了文件结束标记EOF,反之如果管道的读
端文件描述符fd[0] 的引用计数减少至0,即没有任何进程需要从管道读取数
据,则针对该管道的写端文件描述符 fd[1] 的write 操作将失败,并引发
SIGPIPE信号(往读端被关闭的管道或socket连接中写数据)。管道容量的大
小默认是65536字节
父子进程通过管道
- 父进程调用pipe函数创建管道,得到两个文件描述符fd[0]、fd[1]指向管道
的读端和写端 - 父进程调用fork创建子进程,那么子进程也有两个文件描述符指向同一管道
- 父进程关闭管道读端,子进程关闭管道写端。父进程可以向管道中写入数据
,子进程将管道中的数据读出。由于管道是利用环形队列实现的,数据从写端
流入管道,从读端流出,这样就实现了进程间通信
共享内存函数
参考
1 | https://cloud.tencent.com/developer/article/1797468?from=information |
共享内存函数由shmget、 shmat、 shmdt、 shmctl 四个函数组成
shmget
调用成功返回一个shmid(类似打开一个或创建一个文件获得的文件描述符一样)
调用失败返回-1
1 | int shmget(key_t key, size_t size, int shmflg) |
- key 有两种分配共享内存的方式,一般用来亲缘关系的进程间通信
- IPC_PRIVATE 创建一块新的共享内存
- size 是要建立共享内存的长度。所有的内存分配操作都是以页为单位的
- shmflg 指定创建或打开的标志和读写的权限
- IPC_CREAT 如果共享内存不存在,则创建一个共享内存,否则直接打开已存在的
- IPC_EXCL 只有在共享内存不存在的时候,新的内存才建立,否则就产生错误
shmat
将标示符为shmid共享内存映射到调用进程的地址空间中,调用成功返回映射后
的地址,出错返回-1
1 | void * shmat(int shmid, const void *shmaddr, int shmflg); |
- shmid:要映射的共享内存区标示符
- shmaddr:将共享内存映射到指定地址(若为NULL,则表示由系统自动完成映射)
- shmflg:SHM_RDONLY 共享内存只读,默认0表示共享内存可读写
shmdt
撤销共享内存与用户进程之间的映射,当一个进程不再需要共享内存段时,它
将调用shmdt()系统调用取消这个段,但是这并不是从内核真正地删除这个段
,而是把相关shmid_ds结构的shm_nattch域的值减1,当这个值为0时,内核
才从物理上删除这个共享段
1 | int shmdt(const void * shmaddr); |
- 参数shmaddr 是shmat 映射成功返回的地址
shmctl
1 | int shmctl(int shmid, int cmd, struct shmid_ds *buf); |
- shmid 共享内存标示符ID
- cmd IPC_STAT得到共享内存的状态,IPC_SET改变共享内存的状态,IPC_RMID
删除共享内存
阻塞和非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态
- 阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到
结果之后才会返回,比如现在我们的程序想要通过网络读取数据,如果是阻塞
IO模式,一旦发起请求到操作系统内核去从网络中读取数据,就会阻塞在那里
,必须要等待网络中的数据到达了之后,才能从网络读取数据到内核,再从内
核返回给程序 - 非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程,程序
发送请求给内核要从网络读取数据,但是此时网络中的数据还没到,此时不
会阻塞住,内核会返回一个异常消息给程序,程序可以干点别的,然后不断
去轮询去访问内核,看请求的数据是否读取到了
同步和异步
同步和异步关注的是消息通信机制
- 同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但
是一旦调用返回,就得到返回值了,就是由调用者主动等待这个调用的结果,
用者必须要等待这个接口的磁盘读写或者网络通信的操作执行完毕了,调用者
才能返回 - 异步,调用在发出之后,这个调用就直接返回了,所以没有返回结果,当
一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被
调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用