
1
参考
《Redis设计与实现》 遇见狂神说
NoSql概述
单机MySQL的年代 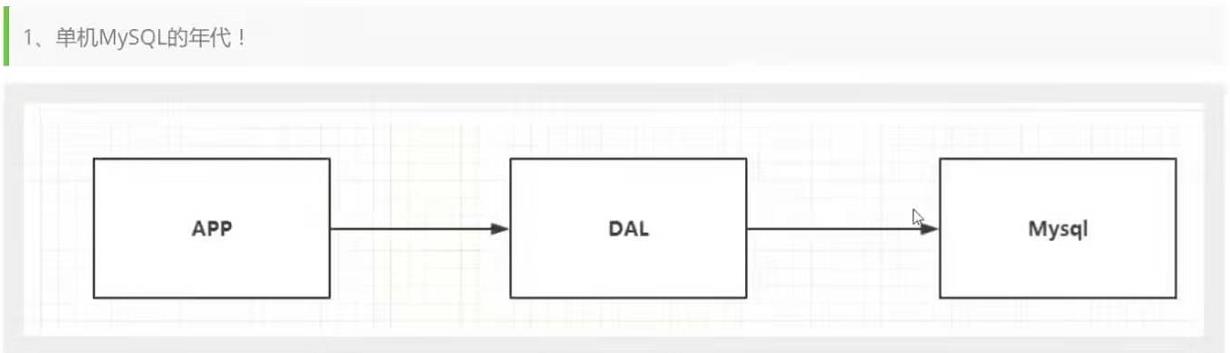
Memcached(缓存)+Mysql+垂直拆分(读写分离) 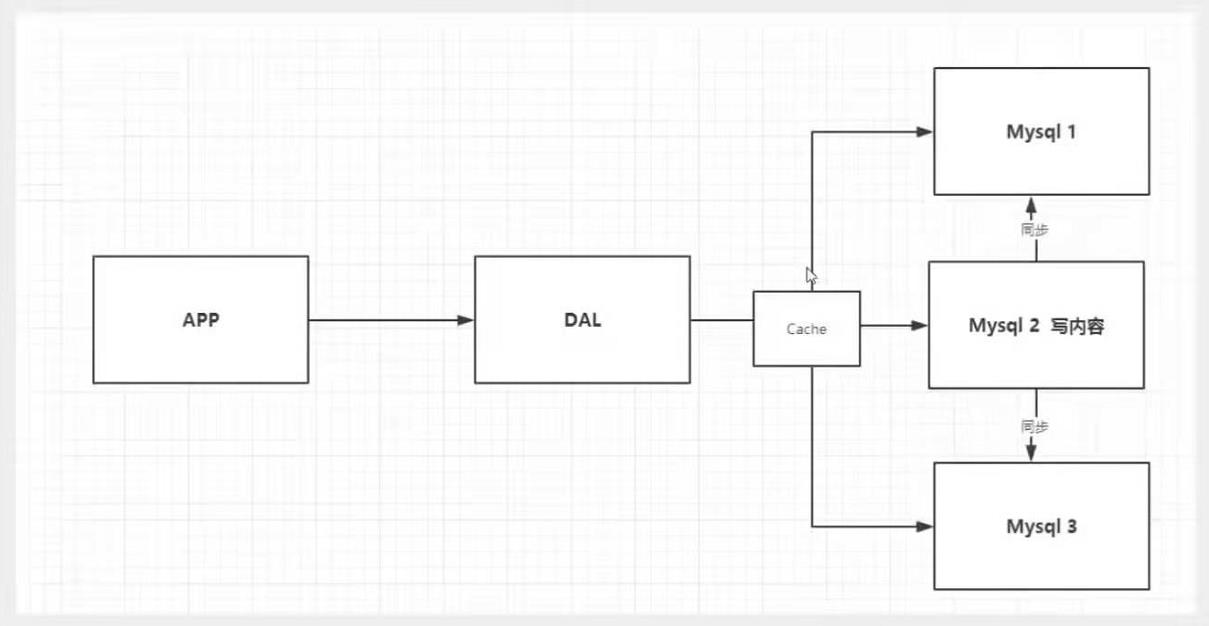
分库分表+水平拆分+MySQL集群 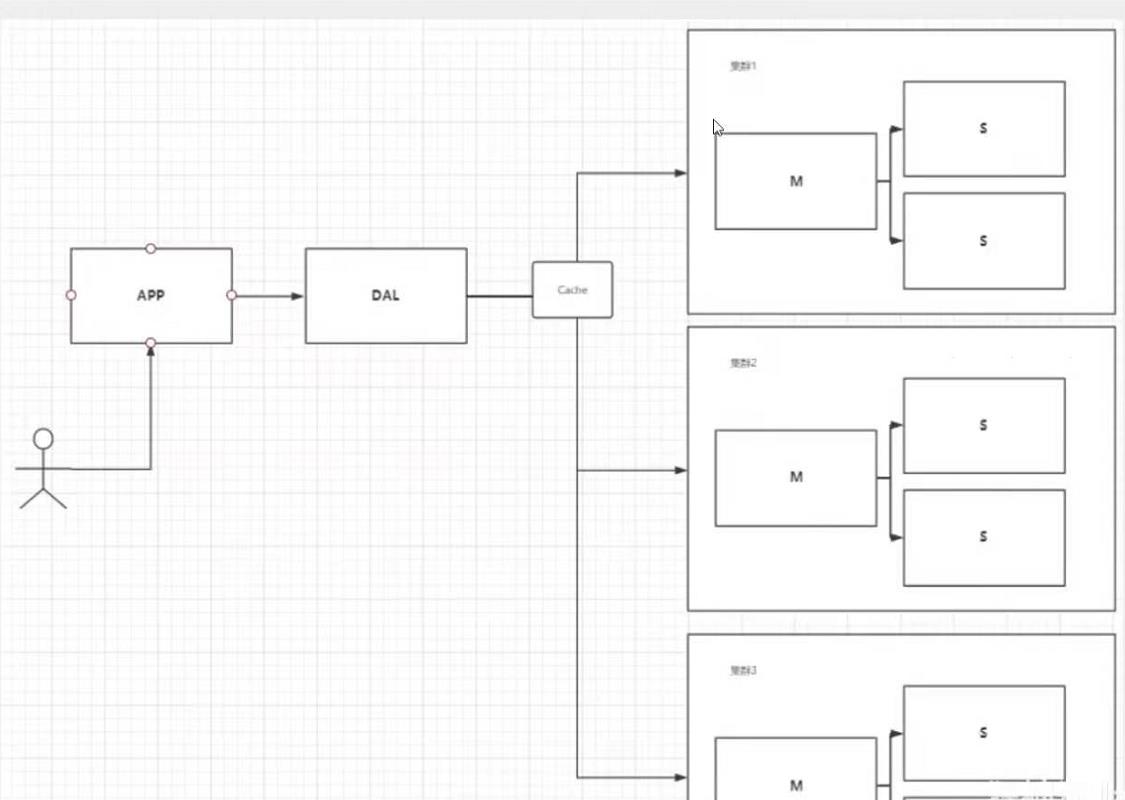
NoSQL not only sql不仅仅是数据库,泛指非关系型数据库。传统的关系型数据
库无法应对大数据,NoSQL在当今大数据时代发展瞬速。很多的数据类型比如用户
的个人信息、社交网络、地理位置等并不需要一个固定的格式,不需要多余的操作
就可以横向扩展
横向扩展和纵向扩展
横向扩展:多增加几台API服务器,一起服务。也叫水平扩展,用更多的节点支撑更
大量的请求。 如成千上万的蚂蚁完成一项搬运工作
纵向扩展:把API服务器换成性能更好的机器。又叫垂直扩展,扩展一个点的能力支
撑更大的请求。如利用1个人的能力,如蜘蛛侠逼停火车
NoSql特点
- 方便扩展,数据之间没有关系
- 大数据高性能(Redis一秒写8万,读取11万)缓存记录级、细粒度
- 数据类型是多样型的,不需要事先设计数据库,随取随用
- 不仅仅保存数据
- 没有固定的查询语言
- 键值对存储、列存储、文档存储、图形数据库
- 最终一致性
- CAP定理(一致性(Consistency)、可用性(Availability)、分区容错性,
这三个要素最多只能同时实现两点)和BASE(基本可用(Basically Available)
软状态(Soft state)最终一致(Eventually consistent)) - 高性能、高可用、高可扩
- 关系型数据库特点
- 结构化组织
- SQL
- 数据和关系都存储在单独的表中
- 有专门的数据操作以及数据定义语言
- 严格的一致性原则
NoSQL四大分类

- KV键值对
- Redis
- 文档型数据库 boson格式,和json一样
- MongoDB 基于分布式文件存储的数据库,主要用来处理大量文档,是介于
关系型数据库和菲关系型数据库之间的产品 - ConthDB
- 列存储数据库
- HBase
- 分布式文件系统
- 图关系数据库
- Neo4j
- InfoGrid
Redis概述
Remote Dictionary Server,即远程字典服务
- 内存存储,持久化(rdb aof)
- 效率高,可以用于高速缓存
- 发布订阅系统
- 地图信息分析
- 计时器
Linux下载Redis
我在VMware虚拟机中创建centos,用xhell远程连接
如果有网络问题请参考 https://www.bbsmax.com/A/rV57Qk3jzP/
下载Redis压缩文件,通过pscp从windows系统传送到Linux系统
注意最新的版本也就是6开头的话gcc的版本也要是最新的,这里我用了旧版本
pscp -r D:\shared\redis-5.0.10.tar.gz root@IP:/opt 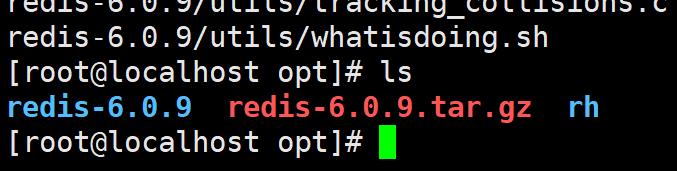
Redis配置
进入Redis-5.0.10可以查看所有文件,redis.conf是配置文件 
安装 yum install gcc-c++ ,Redis是用C++写的
安装完成后执行 make & make install 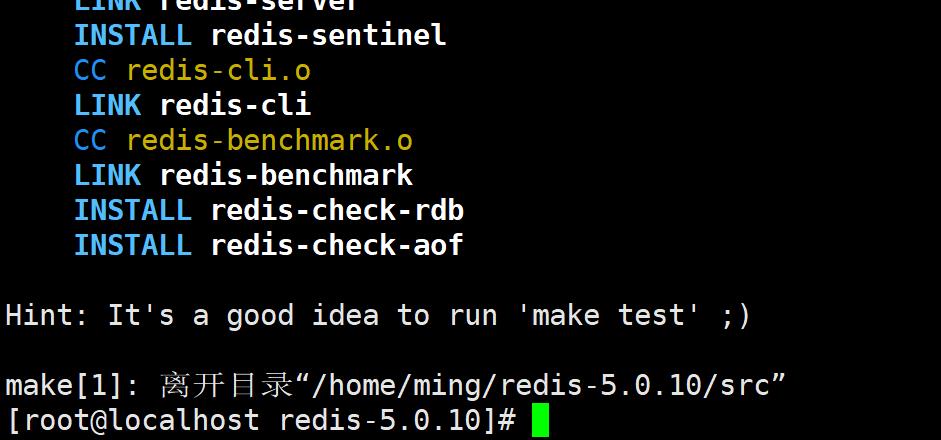
Redis的默认安装路径在/usr/local/bin 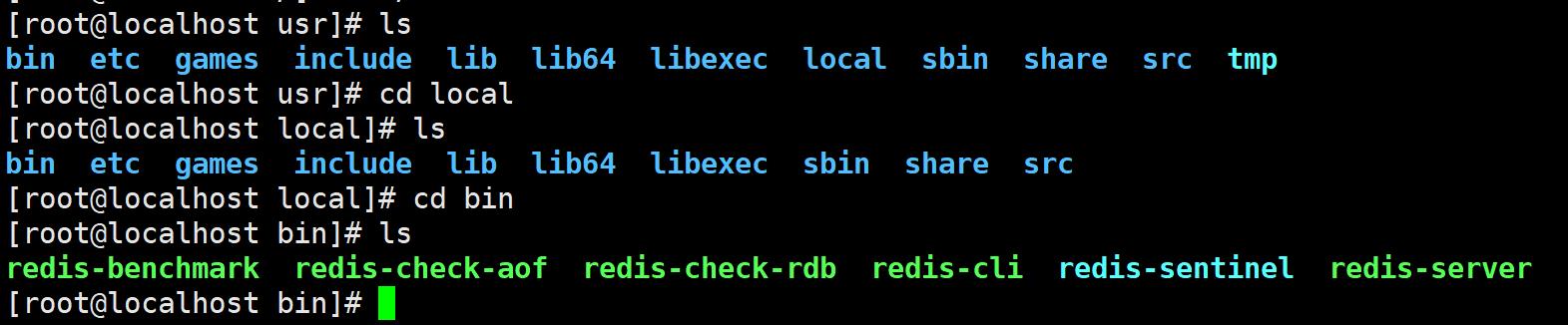
cp /home/ming/redis-5.0.10/redis.conf kconfig 将配置文件复制一份
编辑redis.conf文件,将daemonize改为yes,默认后台启动
启动redis 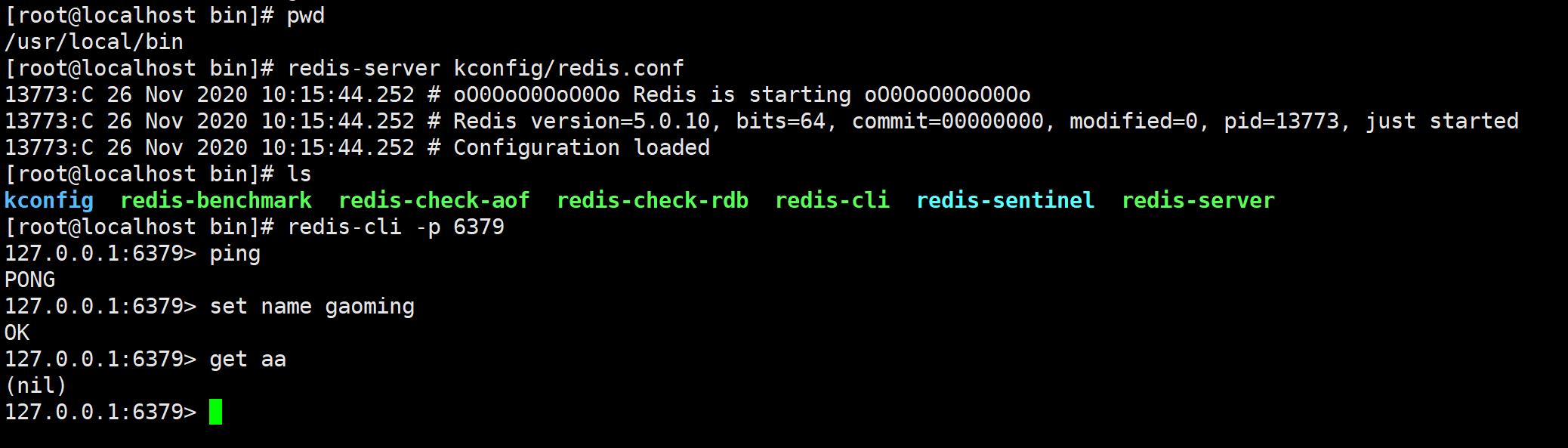
关闭redis 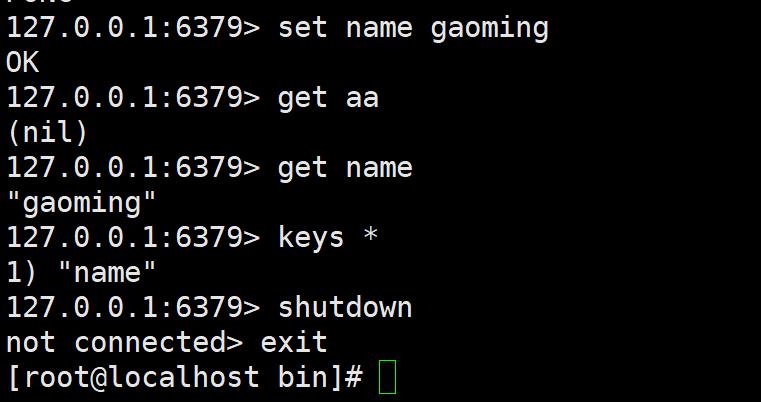
测试性能
redis-benchmark是一个压力测试工具 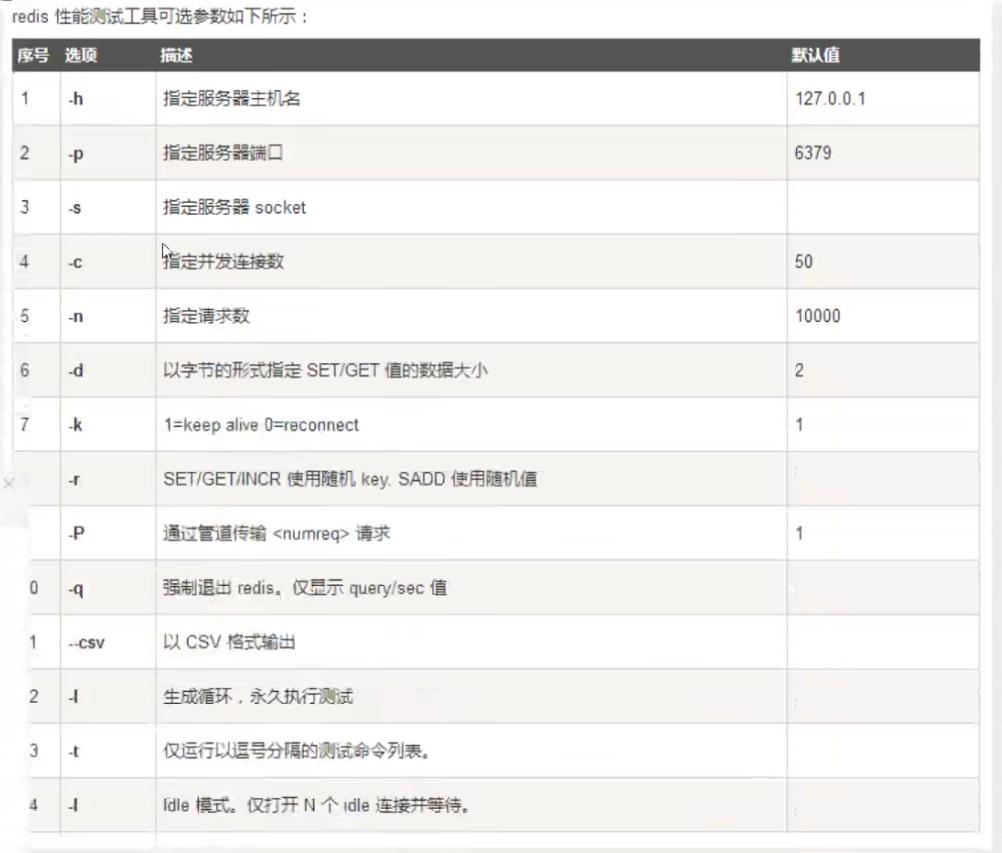
比如现在来测试100个并发连接和100000个请求
redis-benchmark -h localhost -p 6379 -c 100 -n 100000 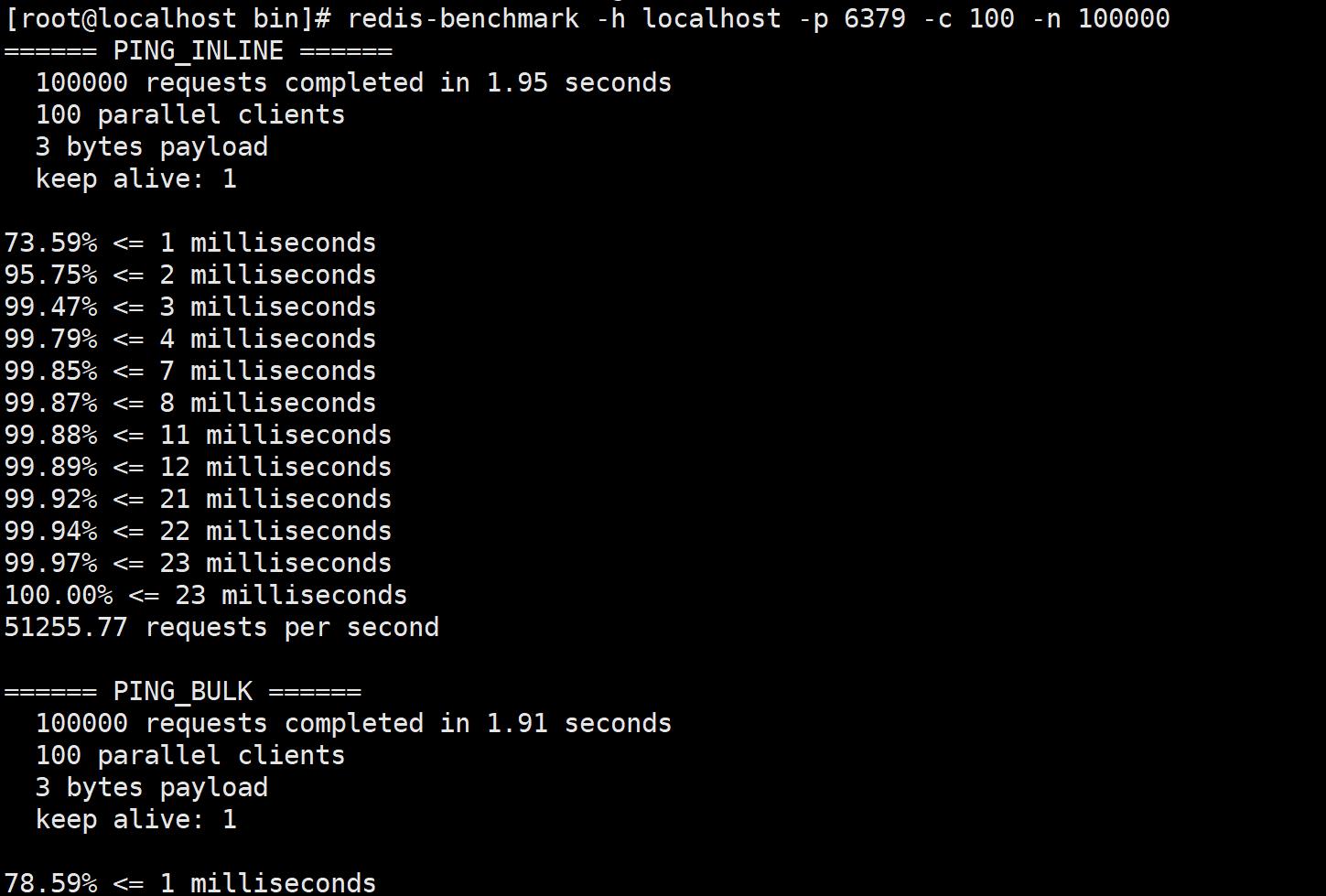
对100000个请求进行写入测试,一共有100个并发客户端,每次写入3个字节,
只有一台服务器处理这些请求,每秒能够处理51255.77个请求
Redis
以上的所有操作都能完成后就可以正式学习Redis了
基础知识
Redis默认有16个数据库,可以查看redis.conf文件,默认使用的是第0个
数据库
1 | select index #index就是指定使用哪个数据库 |
Redis是单线程的,Redis是基于内存操作,CPU不是Redis的性能瓶颈,Redis
的瓶颈是根据机器内存和网络带宽,既然可以使用单线程就使用了呗。Redis是
用C语言写的,官方提供的数据为100000+的QPS,Redis有以下误区
- 高性能服务器一定是多线程?
- 多线程一定比单线程效率高?
Redis是将所有的数据全部放入内存中,所以使用单线程是最快的,因为多线程
会存在CPU上下文切换耗时
五大基本数据类型
通过官方介绍可以知道Redis可以用作数据库、缓存和消息中间件MQ。支持多种
类型的数据结构 string,hashes,lists,sets,sorted sets和范围查询,
bitmaps,hyperloglogs和地理空间索引半径查询 
Redis-Key
1 | move key 1 #将key移动到指定数据库 |
String
1 | getrange key start end #查看从start到end的字符串,从0开始如果end为-1则为全部 |
三大特殊类型
geospatial
这个功能可以推算地理位置的信息,两地之间的距离,方圆几里的人。底层原理是Zset
1 | geoadd china:city 114.109 22.544 shenzhen |
Hyperloglog
占用的内存是固定的
1 | pfadd key xx #添加元素,重复的元素实际上不会成功添加 |
Bitmap
位存储,比如每天打卡就可以使用0或1来表示
1 | setbit key offset value |
事务
Redis单条命令是具有原子性的,但是Redis的事务是不具有原子性的
- 开启事务使用 multi
- 命令入队 所有操作先不执行,只有发起执行命令才会执行
- 执行命令 exec 一次性、顺序性、排他性
- 取消事务 discard 之前入队的操作都不会被执行
对于一个事务,如果这个事务中存在错误命令等情况,所有命令都不会被执行,
如果命令没错但是运行时出现错误,其余正确的操作依然可以正常运行
Redis实现乐观锁
- 悲观锁:认为什么时候都会出问题,无论做什么都会加锁
- 乐观锁:认为什么时候都不会出问题,无论做什么都不加锁。更新数据的时候
会判断一下数据是否被修改,如果数据被修改则更新失败
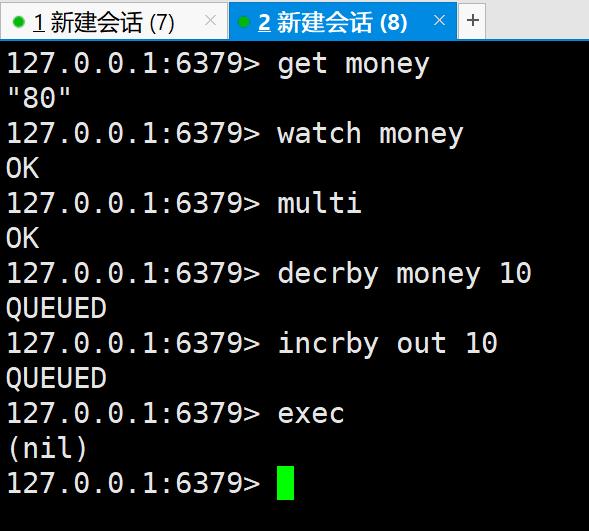
现在开启两个线程,一开始money为80,在新建会话8中监视money并开启事务,
此时先不执行事务,在新建会话7中修改money为1000,然后在会话8中执行事
务,可以看到事务执行失败,watch可以当做redis的乐观锁操作,unwatch
可以解锁放弃监视 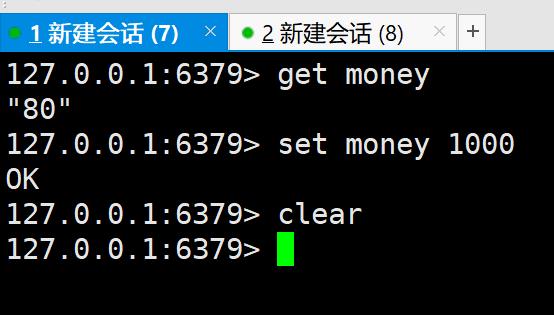
Redis配置文件详解
Redis启动的时候就通过配置文件来启动
- 默认单位 配置文件unit单位对大小写不敏感
1
2
3
4
5
6
7
8# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# units are case insensitive so 1GB 1Gb 1gB are all the same. - 可以包含多个配置文件
1
2# include /path/to/local.conf
# include /path/to/other.conf - 网络
1
2bind 127.0.0.1 #默认在本地访问
port 6379 - 通用配置
1
2
3
4
5
6
7
8
9daemonize yes #以守护进程的方式运行
pidfile /var/run/redis_6379.pid #如果以后台方式运行就需要指定一个pid文件
databases 16 #默认有16个数据库
#redis是内存数据库,如果没有持久化那么数据断点即失
save 900 1 #如果900s内至少有一个key被修改就进行持久化操作
save 300 10 #300s内至少10个key被修改则进行持久化操作
save 60 10000 #60s内有至少10000个key被修改则进行持久化操作
stop-writes-on-bgsave-error yes #持久化出错是否还要继续工作
rdbcompression yes #是否压缩rdb文件,需要消耗一些CPU资源 - 安全
Redis默认是没有密码的,可以通过set requirepass xxx 来设置,登录的
时候 auth xxx 输入密码即可1
# requirepass foobared
- 限制
1
2
3
4最多10000个客户端连接过来
maxclients 10000
maxmemory <bytes> #可以配置的最大内存
maxmemory-policy noeviction #内存到达上限之后的处理策略 - aof配置
1
appendonly no #默认不开启,默认使用rdb持久化
RDB
之前就已经提过,Redis是内存数据库,如果不将内存中的数据库状态保存
到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失,所
Redis提供了持久化功能 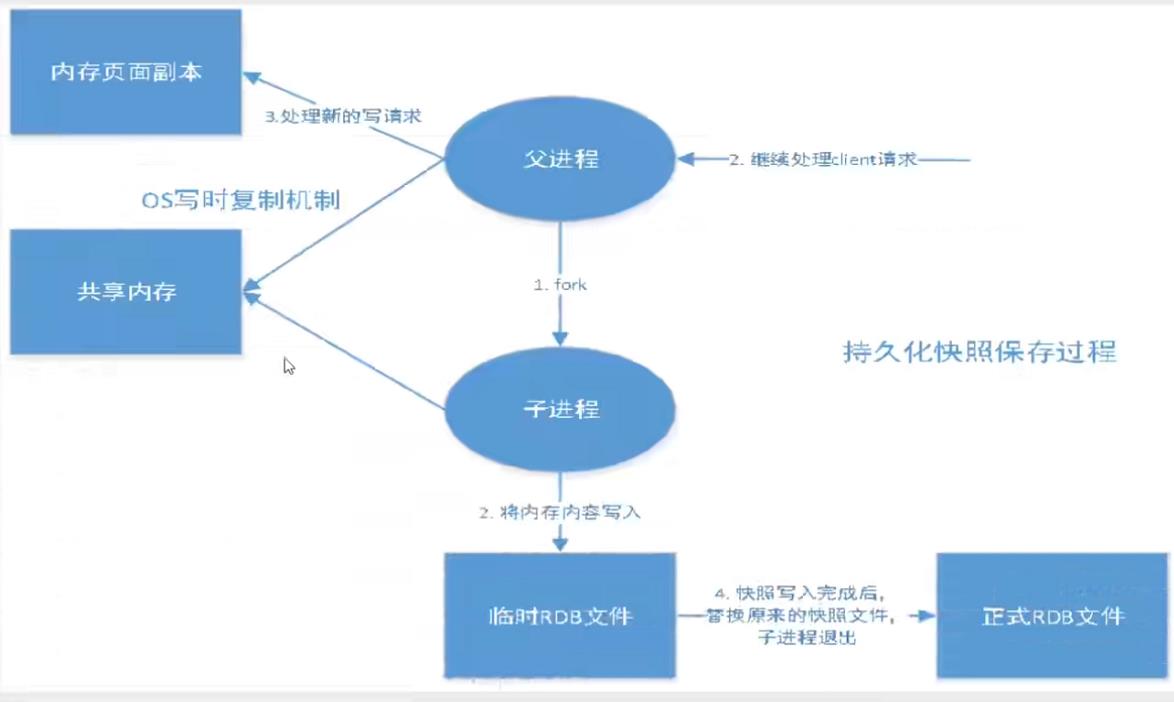
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是Snapshot快
照,它恢复时是将快照文件直接读到内存里。Redis会单独创建一个子进程
来进行持久化,先会将数据写到一个临时文件中,等持久化过程都结束了,
再用这个临时文件替换上次持久化好的文件,整个过程主进程不进行任何
IO操作,这就确保极高的性能。如果需要对大规模数据进行恢复,且对于
数据恢复的完整性不是非常敏感,那么RDB就比AOF更加高效,RDB的缺
点是最后一次持久化的数据可能丢失
- 优点 适合大规模的数据恢复,对数据的完整性要求不高
- 缺点 需要一定时间间隔进程操作
AOF
将所有命令都记录下来,恢复的时候就把这个文件全部都执行一遍 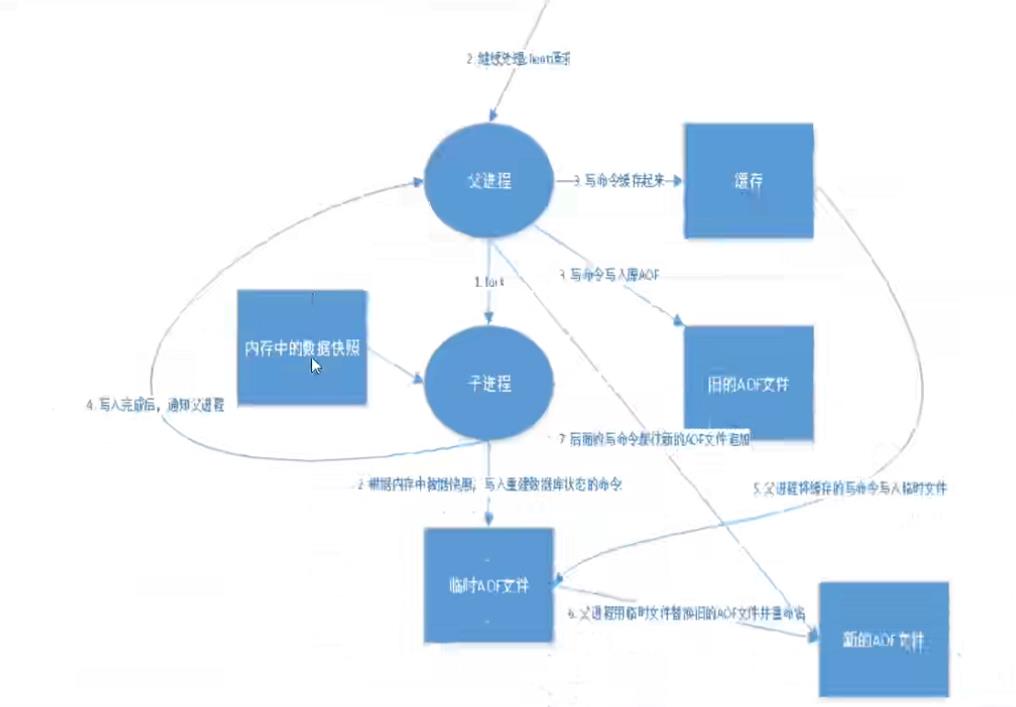
以日志的形式记录每个写操作,将Redis执行过的所有命令记录下来(读
操作不记录),只许追加文件但不可以改写文件,Redis启动之初会读取
该文件重新构建数据,也就是说Redis重启的话就根据日志文件的内容将
写指令从前到后执行一次以完成数据的恢复工作
Redis是什么?
Redis本质上是一个Key-Value 类型的内存数据库,很像memcached,整个数
据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到
硬盘上进行保存
Redis的优缺点?
- 优点
- 因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过10万次读
写操作,是已知性能最快的Key-Value DB - 支持保存多种数据结构,此外单个value的最大限制是1GB,不像memcached
只能保存1MB的数据,因此Redis可以用来实现很多有用的功能
- 缺点
- 是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此
Redis适合的场景主要局限在较小数据量的高性能操作和运算上
关系型数据库和非关系型数据库的区别?
- 数据存储结构 关系型数据库一般都有固定的表结构,比如基于文档的,K-V
键值对的,还有基于图的等,对于数据的格式十分灵活没有固定的表结构,方
便扩展 - 可扩展性 关系型数据库横向扩展难,不好对数据进行分片等,而一些非关
系型数据库则原生就支持数据的水平扩展(比如mongodb的sharding机制) - 数据一致性 非关系型数据库一般强调的是数据最终一致性,而不没有像
ACID 一样强调数据的强一致性,从非关系型数据库中读到的有可能还是处
于一个中间态的数据,因此如果你的业务对于数据的一致性要求很高,那么
非关系型数据库并不一个很好的选择,非关系型数据库可能更多的偏向于
OLAP(联机分析处理)场景,而关系型数据库更多偏向于OLTP场景
横向扩展和纵向扩展的区别?
- 横向扩展:多增加几台API服务器,一起服务。也叫水平扩展,用更多的节
点支撑更大量的请求。 如成千上万的蚂蚁完成一项搬运工作 - 纵向扩展:把API服务器换成性能更好的机器。又叫垂直扩展,扩展一个点
的能力支撑更大的请求。如利用1个人的能力,如蜘蛛侠逼停火车
Redis为什么这么快?
- 完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存
中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1) - 数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者
多线程导致的切换而消耗CPU,不用去考虑各种锁的问题,不存在加锁释放锁操
作,没有因为可能出现死锁而导致的性能消耗 - 使用多路I/O复用模型,非阻塞IO
- 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协
议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的
话,会浪费一定的时间去移动和请求
Redis相比memcached有哪些优势?
- redis支持更丰富的数据类型(支持更复杂的应用场景):Redis不仅仅支持
简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储
。memcache支持简单的数据类型,String - Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候
可以再次加载进行使用,而Memecache把数据全部存在内存之中。 - 集群模式:memcached没有原生的集群模式,需要依靠客户端来实现往集
群中分片写入数据,但是 redis 目前是原生支持 cluster 模式的 - Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的多路
IO 复用模型
Redis 的数据类型?
Redis 支持五种数据类型:string(字符串),hash(哈希),list(列表)
,set(集合)及 zset sorted set:有序集合
- string:redis 中字符串 value 最大可为512M。可以用来做一些计数功
能的缓存(也是实际工作中最常见的)。 常规计数:微博数,粉丝数等 - list:简单的字符串列表,按照插入顺序排序,可以添加一个元素到列表
的头部(左边)或者尾部(右边),Redis list的实现为一个双向链表,即
可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。可
以实现一个简单消息队列功能,做基于redis的分页功能等。可以通过lrange
命令,就是从某个元素开始读取多少个元素,可以基于list 实现分页查询,
类似微博那种下拉不断分页,微博的时间轴 - set:是一个字符串类型的无序集合。可以用来进行全局去重等。(比如:在
微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存
在一个集合。Redis可以非常方便的实现如共同关注、共同粉丝、共同喜好等功
能。这个过程也就是求交集的过程) - sorted set:是一个字符串类型的有序集合,给每一个元素一个固定的分
数score来保持顺序。可以用来做排行榜应用或者进行范围查找等 - hash:键值对集合,是一个字符串类型的Key和 Value 的映射表,也就是
说其存储的Value是一个键值对(Key- Value)hash 特别适合用于存储对象
,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如
我们可以 hash 数据结构来存储用户信息,商品信息等等
Redis三大特殊类型?
geospatial Hyperloglog Bitmap
- geospatial 这个功能可以推算地理位置的信息,两地之间的距离,方圆几
里的人 - Hyperloglog 用来做基数统计的算法,占用的内存是固定的,因为其只会
根据输入元素来计算基数,而不会储存输入元素本身,基数=不重复元素的个
数。一个人访问了一个网站多次,但是还是算作一个人 - 通过一个bit位来表示某个元素对应的值或者状态,可以用来统计用户信息
,登陆,未登录,打卡
Redis的常用场景?
- 计数器 可以对String 进行自增自减运算,从而实现计数器功能。Redis
这种内存型数据库的读写性能非常高,很适合存储频繁读写的计数量 - 排行榜 集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操
作的时候变的非常简单,Redis 只是正好提供了这两种数据结构 - 会话缓存 可以使用 Redis 来统一存储多台应用服务器的会话信息。当应用
服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意
一个应用服务器,从而更容易实现高可用性以及可伸缩性
redis 持久化机制是什么?
Redis提供了两种不同的持久化方法可以将数据存储在磁盘中,一种叫快照RDB,
另一种叫只追加文件AOF
- RDB 在指定的时间间隔内将内存中的数据集快照写入磁盘(Snapshot),它
恢复时是将快照文件直接读到内存里。Redis 会单独创建(fork)一个子进程来
进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再
用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何
IO 操作的,这就确保了极高的性能如果需要进行大规模数据的恢复,且对于
数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB
的缺点是最后一次持久化后的数据可能丢失
- 优点 适合大规模的数据恢复 对数据完整性和一致性要求不高
- 缺点 在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢
失最后一次快照后的所有修改
- AOF 以日志的形式来记录每个写操作,将Redis 执行过的所有写指令记录
下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读
取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写
指令从前到后执行一次以完成数据的恢复工作。
AOF保存的是appendonly.aof文件,采用文件追加方式,文件会越来越大为避
免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时,
Redis 就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集
- 优点 每次发生数据变更会被立即记录到磁盘,性能较差但数据完整性比较好
redis 底层的数据结构?
有8种底层数据结构
- string 字符串对象的编码可以是int、raw或者embstr,如果一个字符串的
内容可以转换为long,那么该字符串就会被转换成为long类型,对象的ptr就
会指向该 long,并且对象类型也用 int 类型表示。普通的字符串有两种,
embstr和raw。。如果字符串对象的长度小于39字节,就用embstr对象。否
则用传统的raw对象 - 哈希对象 ziplist或者hashtable
- 列表对象 ziplist或者linkedlist
- 集合对象 intset或者hashtable,intset是一个整数集合,里面存的为
某种同一类型的整数 - 有序集合对象 一种是ziplist,另一种是skiplist与dict的结合
Redis 常见命令?
- string get 、 set 、 del 、 incr、 decr
- Hash hget 、hset 、 hdel
- List
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
- Set sset 、srem、scard、smembers、sismember
- zset zadd 、 zrange、 zscore
跳跃表是什么?
- 跳表全称为跳跃列表,它允许快速查询,插入和删除一个有序连续元素的
数据链表。跳跃列表的平均查找和插入时间复杂度都是O(logn) - 快速查询是通过维护一个多层次的链表,且每一层链表中的元素是前一层
链表元素的子集,本质是对链表加多级索引 - 一开始时,算法在最稀疏的层次进行搜索,直至需要查找的元素在该层两
个相邻的元素中间。这时,算法将跳转到下一个层次,重复刚才的搜索,直到
找到需要查找的元素为止
字符串类型是怎么实现的?
- 在redis的字符串类型对象中,底层都是采用的是简单动态字符串SDS
数据结构来实现 - SDS 也叫简单动态字符串
- C 字符串中他本身不记录自身的长度信息,所有为了获取一个C字符串的
长度,程序必须遍历整个字符串,对每个字符进行计数,直到遇到空字符为
止,时间复杂度O(N)。和C字符串相比SDS在len属性中记录了字符串本身的
长度信息,因此获取SDS长度的时间复杂度O(1),这极大程度上提高了性能 - C字符串还会容易产生缓冲区溢出,SDS的空间分配完全杜绝了发生缓冲
区溢出的可能性
分布式锁是什么?
为了防止分布式系统中的多个进程之间相互干扰,我们需要一种分布式协调
技术来对这些进程进行调度。而这个分布式协调技术的核心就是来实现这个
分布式锁
分布式锁应该具备哪些条件?
- 在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行
- 高可用的获取锁与释放锁
- 高性能的获取锁与释放锁
- 具备可重入特性
- 具备锁失效机制,防止死锁
- 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败
分布式锁的实现有哪些
- Memcached:利用 Memcached 的 add 命令。此命令是原子性操作,只有
在key 不存在的情况下,才能add 成功,也就意味着线程得到了锁 - Redis:和 Memcached 的方式类似,利用 Redis 的setnx 命令。此命令
同样是原子性操作,只有在key 不存在的情况下,才能set 成功 - Zookeeper:利用 Zookeeper 的顺序临时节点,来实现分布式锁和等待
队列。Zookeeper 设计的初衷,就是为了实现分布式锁服务的 - Chubby:Google 公司实现的粗粒度分布式锁服务,底层利用了Paxos
一致性算法
Redis 实现分布式锁?
- 加锁 使用SETNX指令插入一个键值对,如果Key 已经存在,那么会返回
False,否则插入成功并返回 True,说明key 原本不存在,该线程成功得
到了锁 - 当得到锁的线程执行完任务,需要释放锁,以便其他线程可以进入。释放
锁的最简单方式是执行del 指令 - 锁超时 如果一个得到锁的线程在执行任务的过程中挂掉,来不及显式地
释放锁,这块资源将会永远被锁住(死锁),别的线程再也别想进来。所以
,setnx 的key 必须设置一个超时时间,以保证即使没有被显式释放,这
把锁也要在一定时间后自动释放。setnx 不支持超时参数,所以需要额外
的指令 expire
Kafka 是什么?
- Kafka 是一款基于发布与订阅的消息系统。它一般被称为“分布式提交日
志”或者“分布式流平台”。 - kafka的目标是实现一个为处理实时数据提供一个统一、高吞吐、低延迟
的平台
Jedis
Jedis是官方推荐的Java连接开发工具
1 | <!-- https://mvnrepository.com/artifact/redis.clients/jedis --> |
连接redis,如果连接不成功尝试关闭防火墙,反正情况很多
systemctl stop firewalld.service 
1 | public class Test { |
事务
1 | public static void main(String[] args) { |
SpringBoot整合Redis
底层由jedis替换成了lettuce
- jedis 采用的直连,多个线程操作是不安全的
- lettuce 采用netty,实例可以在多个线程中共享,不存在线程不安全的情况配置连接
1
2
3
4<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>RedisTemplate可以操作不同的数据类型,api和Redis指令是对应的1
2spring.redis.host=localhost
spring.redis.port=63791
2redisTemplate.opsForValue().set("user","fsd");
redisTemplate.opsForvalue().get("user");
自定义RedisTemplate
redis不能直接保存没有序列化的对象,所有对象都需要序列化或者通过jackson
转换成字符串
1 |
|
默认的序列化是JDK的序列化,可以自定义序列化方式
1 |
|