
个人简介
力扣地址:https://leetcode-cn.com/u/gao-ming-3/
牛客地址:高-明 https://www.nowcoder.com/profile/883461684
背包问题
数据结构
分治法
将一个大问题分解为若干小问题,每个小问题都是相互独立并且与原问题有
相同的性质,求解小问题的解合并得到原问题的解,以下算法的具体问题求解
代码都已经放在Algorithm666仓库中
回溯法
回溯法的本质是蛮力法,回溯法常使用深度优先搜索遍历,与蛮力法的区别、
在于回溯法会进行剪枝处理,回溯法不一定能够得到最优解
贪心算法
使用较为简单的方法找到局部最优,此时并不能保证该解是全局最优但是也
是一个不差的解,只解决当前局部问题不关心之前和之后的解,不同的贪心
准则可以得到不同的结果
动态规划
- 解决优化问题,将多阶段问题求解转化为一系列单阶段问题求解,找全
局最优,只有某些条件满足的问题才能使用动态规划。 - 状态的无后效性 如果某个阶段状态给定后,则该阶段以后过程的发展
不受该阶段以前各阶段状态的影响,也就是受状态具有马尔科父性。适用于
动态求解的问题具有状态的无后效性 - 策略 各个阶段决策的确定后,就组成一个决策序列,该序列称之为一
个策略,由某个阶段开始到终止阶段的过程称之为子过程,其对应的某个
策略称之为子策略 - Bellman最优性原理 求解问题的一个最优策略序列的子策略序列总是
最优的,则称该问题满足最优性原理。对具有最优性原理性质的问题而言,
如果有一决策序列包含具有非最优的决策子序列,则该决策序列一定不是最优的 - 动态规划的思想实质是分治思想和解决冗余。与分治法类似的是将原问
题分解成若干子问题,先求解子问题,然后从这些子问题的解得到原问题
的解。与分治法不同的是分解的子问题往往不是相互独立的,若用分治法
来解有些共同部分被重复计算了很多次,动态规划利用这种子问题的折叠性
质,对每一个子问题只解一次
图论算法
- 图的基本概念
- 一个图是由一系列的节点和边组成
- 节点的度指的是节点连接的边的条数,有向图有出度和入度
- 简单图指没有多重边且没有自环的图
- 无向图所有节点度数和为边数的两倍
- 有向图所有节点入度数等于出度数等于边数
- 一条路径由一系列的节点组成,并且相邻两个节点之间有一条边相连,
简单路径没有重复 - 树是一个无环连通的无向图
- 生成树是包含图中所有节点的树
- 加权图是每条边都有权值的图
- 环不是简单路径,起点和终点一致
- 稀疏图 E≈V ,稠密图 E≈V^2
- 任意两个节点都有边连接(有向图两个方向都有边)称为完全图
- 连通分支是图中最大的连通子图
- 树的任意两个节点都有唯一的连通路径
邻接表
使用一个链表数组,对于稀疏图有效,可以节省空间,查找边时比较耗时
,矩阵运算不太方便邻接矩阵
使用一个二维数组,对于稠密图有效图的遍历之BFS
使用先进先出的队列,遍历之后可以形成一个BFS树,节点的深度是距离起始
点的最短距离,它首先访问起始顶点的所有邻接点,然后再访问较远的区域图的遍历之DFS
使用先进后出的栈,遍历之后可以形成一个DFS森林,也就是一系列的DFS树
,深度优先搜索在于能够找到与某一顶点邻接且没有访问过的顶点。
图的基本构造
1 | public class Graph |
检测图是否有环
1 | public class Cycle |
检测是否是二分图
如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所
关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称
图G为一个二分图
1 | public class TwoColor |
有向环
1 | public class Digraph |
有向图的强连通性
1 | public class Kosara |
最小生成树
1 | class Edge |
拓扑排序
- 对于一个有向无环图,拓扑排序就是将所有顶点进行排序
,如果ViVj,那么Vi必须排在Vj
之前 - 对全图进行DFS,记录每个节点的结束时间,以节点结束时
间由大到小的顺序输出节点即可 - 每次都删除入度为0的节点
union-find算法
1 | public class UF |
NP问题
- 有些问题能够在多项式级别的算法解出,例如n^2,n^3
- NP问题是指能够在多项式时间内检验一个解是否正确的问题
- 所有NP问题都能在多项式时间内归约成NPC问题
哈希算法
hashCode
这是一个用C语言实现的方法,作用是返回对象的散列码。Java中有几种集合类,
比如Map List一般存放的元素是有序可重复的,Set存放的元素是不可重复的。
判断一个元素是否重复一般使用equals方法,如果一个集合中有数亿的元素,
那么每新加入一个元素都要与这数亿个元素一起比较效率低下。Java集合采用哈
希表来实现查重,当集合要添加一个新元素时,首先调用hashCode方法,然后
经过哈希化得到一个在哈希表中的位置,如果这个位置没有元素就直接加入,否
则与这个位置的链表上的每个元素通过equals方法进行比较
哈希表
哈希表也称为散列表,Hash表是一种根据关键字(key-value)而直接进行访问的
数据结构,它是基本数组将关键字映射到数组的某个下标来加快查找速度,但是
并不完全是数组,可以看成是数组和链表的结合体最重要的问题就是如何把关键
字转换为数组的下标,这个转换的函数为哈希函数,转换的过程叫做哈希化,同
时也有多个键散列到相同索引的情况,散列查找的第二步就是解决冲突碰撞问题
哈希化
散列表是在时间和空间上做出权衡的经典例子。如果没有内存限制,可以直接将
键作为数组的索引,所有的查找工作只需要访问内存一次就可以完成。如果没有
时间限制,可以使用无序数组并进行顺序查找,这样只需要很小的内存空间。哈
希算法在两种极端之间找到了一种平衡,首先就是散列函数的计算,如果有一个
能够保存M个键值对的数组,那么就需要将任意键转化为0~M-1的索引范围。散列
函数和键的类型有关,每种类型的键都需要一个对应的散列函数
正整数
一般采用整数取余法,选择一个大小为素数M的数组,对于任意整数k计算k%M的
余数,M用素数可以均匀地散列散列值
浮点数
将键表示为二进制数然后再使用除留取余数法
字符串
一种叫Horner方法的经典算法用N次乘法、加法和取余来计算一个字符串的散列值
1 | int hash=0; |
软缓存
如果散列值的计算很耗时,那么或许可以将每个键的散列值缓存起来,Java中的
String对象的hashCode()方法就使用了软缓存
1 | public int hashCode() { |
冲突
一个散列函数能够将键转化为数组索引,散列算法的第二步就是碰撞处理
拉链法
将大小为M的数组中的每个元素都指向一条链表,链表中的每个结点都存储了散列
值为该元素索引的键值对。查找分为两步,首先根据散列值找到对应的链表,然后
沿着链表顺序查找相应的键
线性探测法
用大小为M的数组保存N个键值对,其中M>N。需要依靠数组中的空位解决碰撞冲
突,基于这种策略的所有方法统称为开放地址散列表
- 线性探测 一个位置一个位置按顺序查找,但是很容易发生在某个索引位置聚
集,就好像围观群众一样在某个地方越来越大 - 二次探测 二次探测是防止聚集的一种方式,每次不是相邻位置探测而是探测
间隔位置。二次探测就是x+1 x-1 x+4 x-4 x+9 x-9 - 再哈希法 把关键字用不同的哈希函数再一次哈希,用这个结果作为步长
stepSize=constant-key%constant,constant是质数并且小与数组容量 - 设置公共溢出区法 即为所有冲突的关键字建立一个公共的溢出区来存放,
在查找时,对给定值通过散列函数计算出散列地址后,先与基本表的相应位
置进行比对如果相等,则查找成功如果不相等,则到溢出表去进行顺序查找
,如果对于基本表而言,有冲突的数据很少的情况下,公共溢出区的结构对
查找性能来说还是非常高的
对于hashCode的要求
在程序运行期间,如果对象的变化不会导致equals方法的变化,那么hashCode的
返回值就不能改变
- equals返回true那么hashCode值一定相等
- hashCode值相等不一定equals返回true
常见问题
- 负载因子 α=填入表中元素的个数/hash表长度。哈希法的平均查找长度随
负载因子的增大而增大 - 在内存中的数据查找性能较好的是HashMap,在磁盘中查找性能较好的是
B+ Tree - 开哈希表–链地址法 闭哈希表–开放地址法
脑筋急转弯
- 牛客上有一个题:一个有序数列,序列中的每一个值都能够被2或者3或者5所
整除,这个序列的初始值从1开始,但是1并不在这个数列中。求第1500个值是多少?
两个牛哥的思路:设x个数,x/2+x/3+x/5-x/6-x/10-x/15+x/30=1500
翻译过来是:在x以内,能整除2的有x/2个数,整除3的有x/3个数…但这些数有
重复的,需要利用容斥原理去重: A∪B∪C = A+B+C - A∩B - B∩C - C∩A +
A∩B∩C
链表
栈
- 牛客上有一个算术表达式的题,求中缀表达式的后缀形式
- 这里我给出一个中缀表达式:a+b*c-(d+e)
- 第一步:按照运算符的优先级对所有的运算单位加括号:式子变成了
((a+(b*c))-(d+e)) - 第二步:转换前缀与后缀表达式
- 前缀:把运算符号移动到对应的括号前面
- 则变成了:-( +(a *(bc)) +(de))
- 把括号去掉:-+a*bc+de 前缀式子出现
- 后缀:把运算符号移动到对应的括号后面
- 则变成了:((a(bc)* )+ (de)+ )-
- 把括号去掉:abc*+de+- 后缀式子出现
广义表
广义表是一种非线性的数据结构,列表的表头可以是原子或者子表,但是表尾
必须是子表
B树和B+树
参考 https://blog.csdn.net/zhuanzhe117/article/details/78039692
B树
每个节点都存储key和data,所有节点组成这棵树,叶子节点指针为null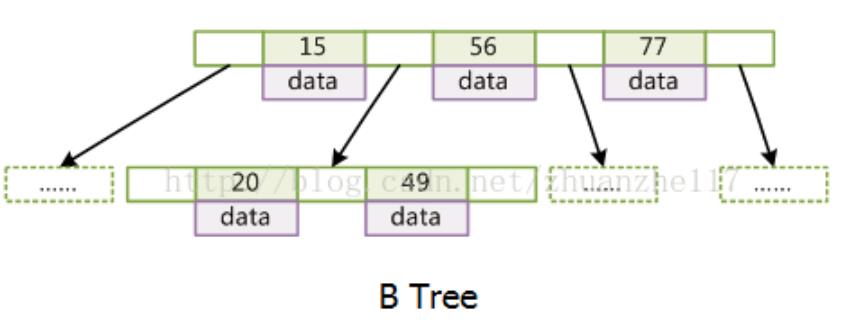
B+树
只有叶子节点存储data,叶子节点包含这棵树所有的键值,叶子节点不存储指针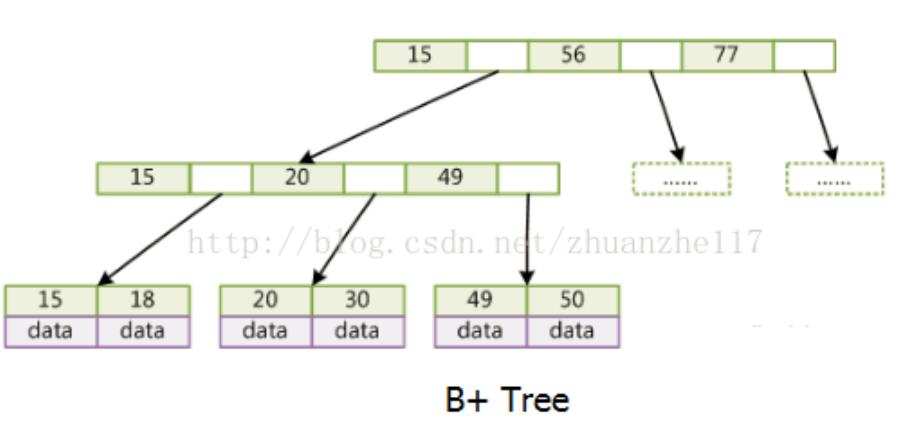
后来B+树上增加了顺序访问指针,也就是每个叶子节点都增加一个指向相邻叶子
节点的指针,这样一棵树成了数据库系统实现索引的首选数据结构
LRU算法
参考 https://www.cnblogs.com/wyq178/p/9976815.html
原意是 Least Recently Used ,即最近最久未使用算法,是由一个著名的操
作系统基础理论得来:最近使用的页面数据会在未来一段时期内仍然被使用,已
经很久没有使用的页面很有可能在未来较长的一段时间内仍然不会被使用。基于
这个思想,会存在一种缓存淘汰机制,每次从内存中找到最久未使用的数据然后
置换出来,从而存入新的数据!它的主要衡量指标是使用的时间,附加指标是
使用的次数
LRU实现
可以利用双向链表实现,双向链表的特点就是链表是双路的,利用先进先出原则
将最近获得的元素最早被获取,添加新元素直接放在链表头上,访问时如果是头
节点不用管,如果访问的是中间位置或尾部就要将其移动到头节点,修改操作跟
访问一样,删除是直接删除该节点。
- 缓存实现:查询、更新,一定是使用HashMap
- 通过链表来判断最近最少使用的是哪一个,即:最近有使用的放链表头、最近
最少使用的放链表尾 - 因为需要删除链表中某个过期的节点,所以选择使用双向链表
- HashMap中key就存查询搜索的key;value存放双向链表的节点定义一个LRU类,然后定义它的大小、容量、头节点、尾节点等部分
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Node {
//键
Object key;
//值
Object value;
//上一个节点
Node pre;
//下一个节点
Node next;
public Node(Object key, Object value) {
this.key = key;
this.value = value;
}
}添加元素的时候首先判断是不是新的元素,如果是新元素,判断当前的大小是1
2
3
4
5
6
7
8
9
10
11public class LRU<K, V> {
private int currentSize;//当前的大小
private int capcity;//总容量
private HashMap<K, Node> caches;//所有的node节点
private Node first;//头节点
private Node last;//尾节点
public LRU(int size) {
currentSize = 0;
this.capcity = size;
caches = new HashMap<K, Node>(size);
}
不是大于总容量了,防止超过总链表大小,如果大于的话直接抛弃最后一个节
点,然后再以传入的key\value值创建新的节点。对于已经存在的元素,直接
覆盖旧值,再将该元素移动到头部,然后保存在map中通过key值来访问元素,主要的做法就是先判断如果是不存在的,直接返回1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public void put(K key, V value) {
Node node = caches.get(key);
//如果新元素
if (node == null) {
//如果超过元素容纳量
if (caches.size() >= capcity) {
//移除最后一个节点
caches.remove(last.key);
removeLast();
}
//创建新节点
node = new Node(key,value);
caches.put(key, node);
currentSize++;
}else {
//已经存在的元素覆盖旧值
node.value = value;
}
//把元素移动到首部
moveToHead(node);
}
null。如果存在,把数据移动到首部头节点,然后再返回旧值在根据key 删除节点的操作中,我们需要做的是把节点的前一个节点的指针1
2
3
4
5
6
7
8
9public Object get(K key) {
Node node = caches.get(key);
if (node == null) {
return null;
}
//把访问的节点移动到首部
moveToHead(node);
return node.value;
}
指向当前节点下一个位置,再把当前节点的下一个的节点的上一个指向当前
节点的前一个接下来实现移动元素到头节点,首先把当前节点移除,类似于删除的效果(但1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public Object remove(K key) {
Node node = caches.get(key);
if (node != null) {
if (node.pre != null) {
node.pre.next = node.next;
}
if (node.next != null) {
node.next.pre = node.pre;
}
if (node == first) {
first = node.next;
}
if (node == last) {
last = node.pre;
}
}
return caches.remove(key);
}
是没有移除该元素),然后再将首节点设为当前节点的下一个,再把当前节点
设为头节点的前一个节点。当前节点设为首节点。再把首节点的前一个节点设
为null,这样就是间接替换了头节点为当前节点1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22private void moveToHead(Node node) {
if (first == node) {
return;
}
if (node.next != null) {
node.next.pre = node.pre;
}
if (node.pre != null) {
node.pre.next = node.next;
}
if (node == last) {
last = last.pre;
}
if (first == null || last == null) {
first = last = node;
return;
}
node.next = first;
first.pre = node;
first = node;
first.pre = null;
}