
前言
承接我的上一篇博客VBlog2。在这里感谢 Evan-Nightly的教程
https://learner.blog.csdn.net/article/details/88925013
https://github.com/Antabot/White-Jotter
Web项目优化解决方案
优秀代码有三个重要部分:代码规范、服务性能、系统安全
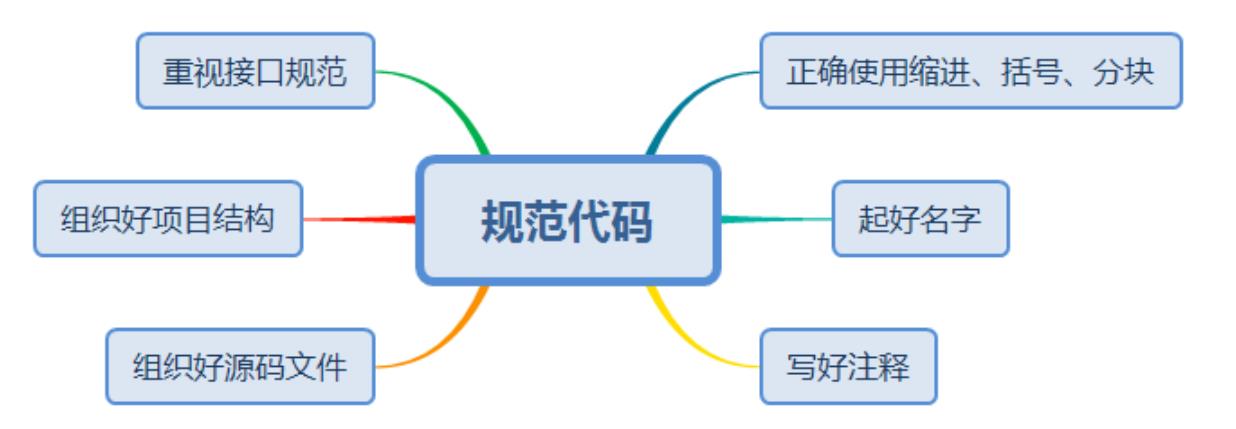
编写代码规范
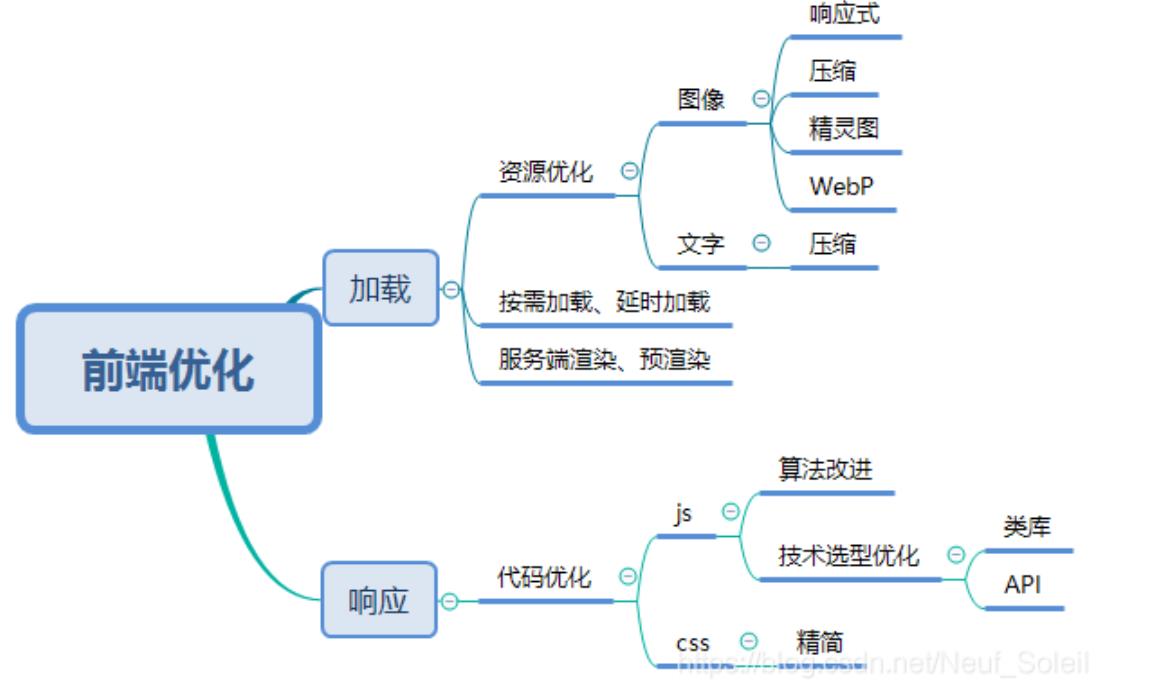
提高服务性能
性能问题,除了算法之外,还要考虑软件架构、软件设计、软件部署,以及
一些具体的优化技巧
- 前端
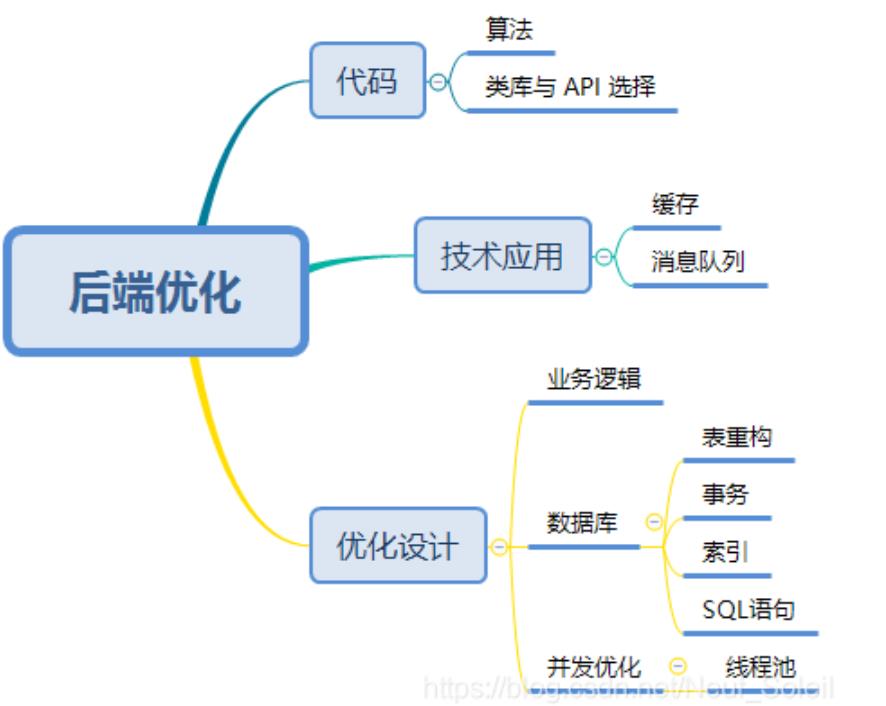
- 后端
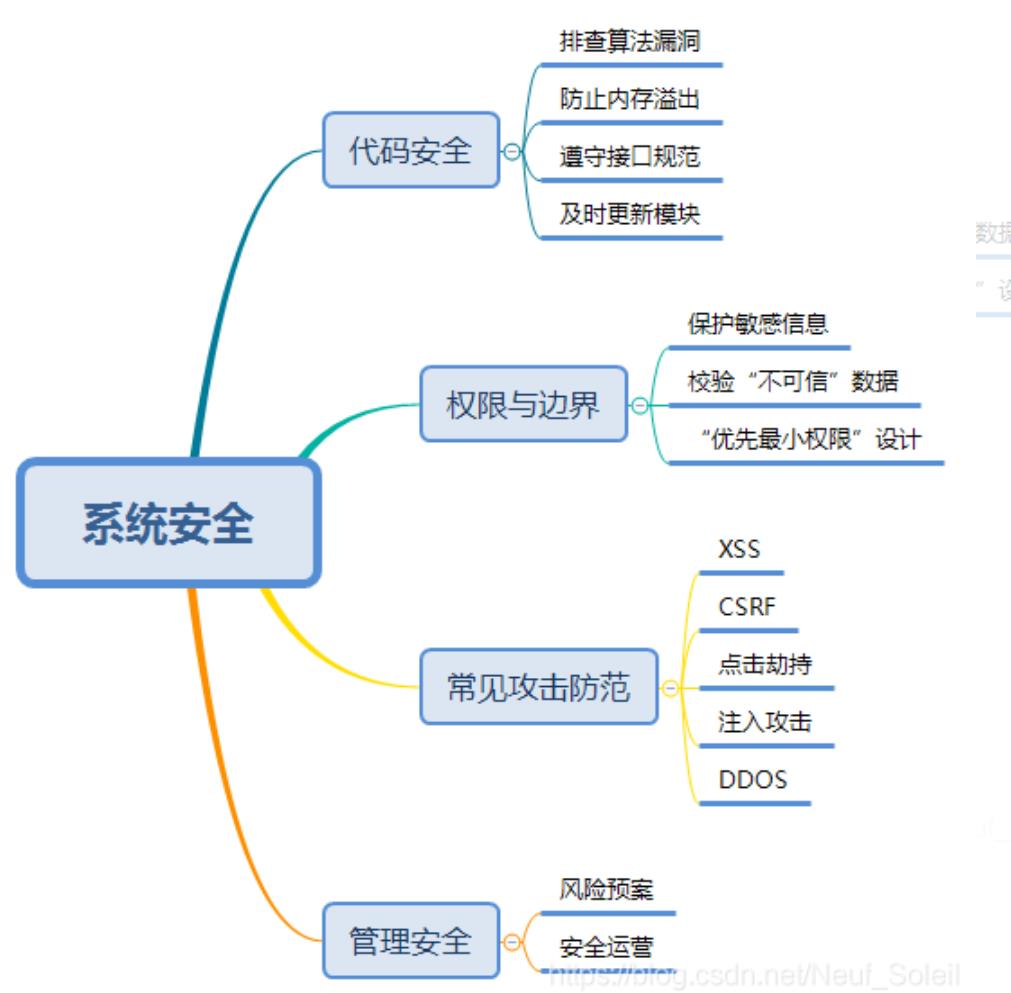
系统安全
前端优化实战
缓存的使用
这是white_jotter项目的最后一篇教程,我从头开始跟着作者敲了一遍,
对前后端分离项目有了初步的了解,在这里再次感谢Evan大佬
缓存
学习过计算机系统都知道在CPU与内存之间存在高速静态随机存储器(SRAM),
CPU的计算速度要远快于内存的读写速度,所以在两者之间使用高速缓存来
提高计算机的运行效率
Web中的缓存
在做项目的过程中经常涉及点之间的衔接,要衔接就会有两个层次的不平衡
- 一是性能的不平衡,包括速率、吞吐量等,造成这种不均衡的原因包括软件
、硬件、网络、协议、策略等、位置多个维度 - 二是数据本身活跃性的不均衡,有些数据会被频繁传递,有些很久才被访问
一次
基于这两个不平衡,诞生了各种缓存方案
- 浏览器缓存,包括本地的页面资源文件和 DNS 映射
- DNS 服务器上的缓存(IP - 域名映射)
- CDN,利用边缘 Cache 服务器提高访问速度
- ORM 框架提供的缓存,比如 Spring Data JPA 的持久化上下文
- 利用高性能非关系型数据库(如 Redis)提供缓存服务,作为对关系型数据库
的补充 - 数据库提供的缓存,比如 MySQL 自带的查询缓存,会把执行语句与查询结果
以K-V 形式缓存在内存中(由于该缓存命中率较低,不建议使用,且 8.0 版本
已删除此功能)
缓存的工作模式
缓存的实际使用可以分为以下几种模式
- Cache-Aside 边缘缓存,缓存作为数据库的补充,数据的获取策略是如果缓存
中存在则从缓存获取,如果不存在则从数据库获取,并写入缓存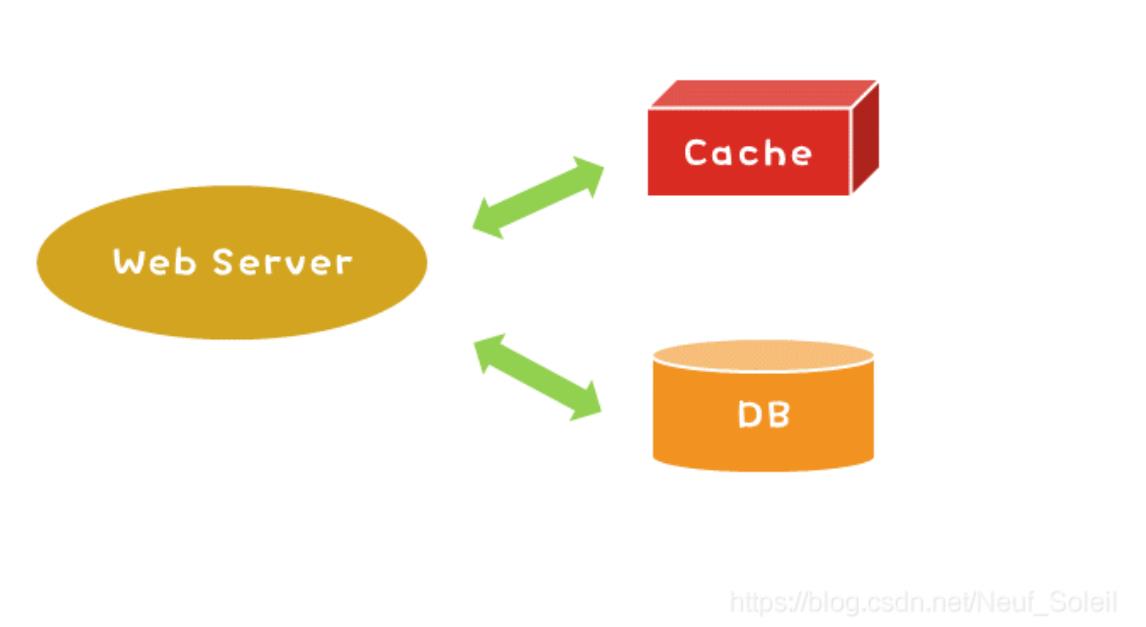
- Read-Through 把数据库藏在缓存背后,一切请求交由缓存响应,如果命中缓存
则由缓存获取,如果没有命中则由数据库查询,写入缓存再由缓存返回,对于这种
模式写入缓存的操作会阻塞请求的响应,一般不用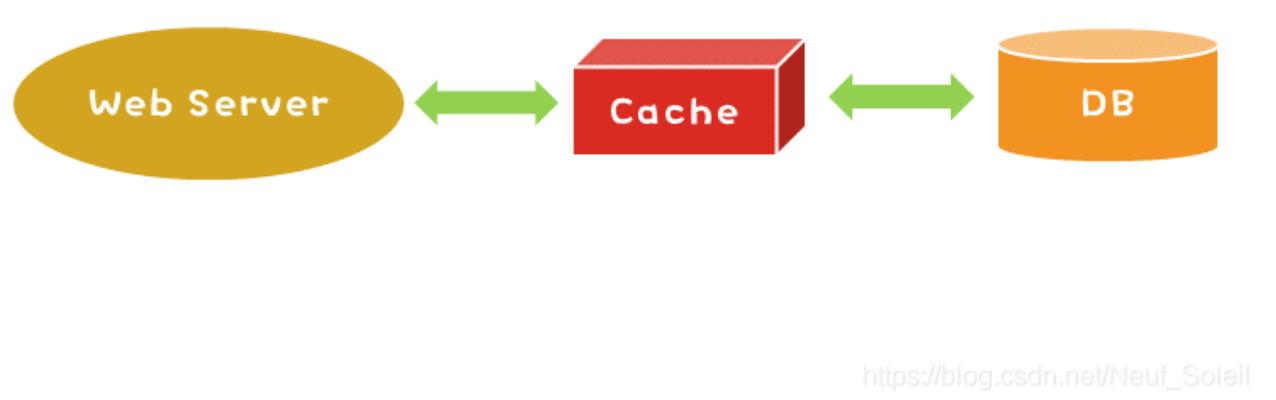
- Write-Through 对于需要动态更新的应用,仅仅通过读操作触发缓存更新肯定
不够,如果数据库更新而缓存没有更新肯定不行,在更新数据库数据时,有两种常
见的操作缓存的模式,该模式的特点就是请求更新数据时,如果该数据在缓存中存
在那么先更新缓存再更新数据库 - Write-Back 请求更新数据,先更新缓存,数据库何时更新不确定,目前只要
有缓存就行,这种异步的方式有数据不一致的风险,但是请求从缓存更新数据确
实足够快,在一些高并发大吞吐量的系统中比较常见,高并发的一个核心解决方
案就是缓存,高并发的复杂性很大程度上取决于缓存的复杂性
缓存的常见问题
在使用缓存时要考虑如下问题
- 数据一致性问题 缓存的数据和数据库中的数据由于各种原因产生差异
- 缓存穿透 虽然使用了缓存但是仍然有请求绕过缓存访问数据库
- 缓存雪崩 一大批缓存同时过期同一又有一大批请求到来,像雪崩一样
数据一致性问题
一个系统中如果数据都是不变的应该使用Cache-Aside模式,可以做到缓存和数据
库中的数据永远一致,需要考虑的就是缓存什么时候过期或者缓存更新的算法,尽
量做到找出热点数据即可。但是大部分系统是需要更新数据的,数据更新了但缓存
没有及时更新有些情况可能不会出现问题,但是在大多数场景不能接受,比如支
付宝,如果数据没能及时更新后果严重。如果在写场景下更新缓存,先更新数据
库再更新缓存
缓存穿透
引发缓存穿透的情形一般有两种情况,一是大量查询数据库中也没有的数据,这种
数据正常在缓存中也没有,但是每次还是必要地访问数据库,可以设置一个规则,
数据库中没有的数据也可以缓存起来,只要设置为空就行。另一种情形是数据库中
有一个数据,之前没人查询过,但是突然一瞬间来了大量的请求,缓存来不及反
应,压力就全到数据库上,有两种处理方法,一是限流,而是预判。限流就是限
制请求量,预判就是提前知道有些数据会被大量访问,提前缓存这些数据,也
叫缓存预热
缓存雪崩
本质上雪崩和穿透是一类问题,只是出现的阶段不一样,穿透是缓存已经稳定建立
起来,雪崩是缓存突然同时过期,还有一种情况就是完全还没有缓存的时候一大波
请求涌入,比如缓存没有做持久化
缓存应用实战
前后端都有缓存,前端缓存应对的是对静态页面资源的访问,本地缓存更具体地说
是同一用户的多次访问,而后端缓存更多地考虑多个用户的多次访问,面向的资源
主要是数据库里的数据。对于这个项目而言前台的图书信息和文章两部分数据库压
力比较大
Redis
Redis和Mysql一样也是数据库管理系统,并不是为了缓存,Redis访问速度快但又
不能完全替代关系型数据库,所以适合用来做关系型数据库的缓存,接下来就使用
Spring Data Redis