
项目云端部署
项目云端部署
使用阿里云服务器
centos下载JDK
1 | wget https://repo.huaweicloud.com/java/jdk/8u201-b09/jdk-8u201-linux-x64.tar.gz |
数据库环境安装
1 | yum install mysql* #安装数据库 |
备份数据库
1 | # Windows |
项目打包
本项目打成jar包,在服务器直接用java -jar运行。maven打jar包首先需要
添加以下属性,以便在打包的时候知道JDK的位置,不然报错
1 | <properties> |
然后添加spring-boot-maven-plugin插件,使打包后的文件能够找到Spring
Boot的入口类,即App.java
1 | <plugins> |
最后在开发目录执行mvn clean package即会清空target并打成jar包
deploy启动脚本
有的时候线上环境需要更改一些配置,比如在9090端口部署等等。Spring
Boot 支持在线上环境中使用spring.config.additional-location指
定线上环境的配置文件,而不是jar包里的配置文件
1 | java -jar soquick.jar --spring.config.addition-location= |
新建一个sh文件,即便console界面退出应用程序也不会退出
1 | nohup java -Xms400m -Xmx400m -XX:NewSize=200m -XX:MaxNewSize=200m |
使用./deploy.sh &即可在后台启动,使用tail -200f nohup.out即可查
看项目启动、运行的信息
jmeter性能压测
本项目使用jmeter来进行并发压测。使用方法简单来说就是新建一个线程组
,添加需要压测的接口地址,查看结果树和聚合报告
- 线程组 启动多个并发线程,并发发送一些接口的请求
- Http请求 发送http请求
- 查看结果树
- 聚合报告
首先添加一个线程组,然后创建http请求,然后添加一个查看结果树,最后
需要添加一个聚合报告
并发容量问题
- 使用pstree -p pid | wc -l命令可以查看Java进程一共维护了多少
个线程,在没有压测的时候,Tomcat维护了31个线程(不同机器该值不一
定)。而进行压测的时候,Tomcat维护的线程数量猛增至200多个 - 使用top -H命令可以查看CPU的使用情况,主要关注us,用户进程占用
的CPU。sy,内核进程占用的CPU。还有load average,这个很重要,反映
了CPU的负载强度 - 在当前线程数量的情况下,发送100个线程,CPU的压力不算太大,所有
请求都得到了处理,而发送5000个线程,大量请求报错,默认的线程数量
不够用了,可见可以提高Tomcat维护的线程数
Spring Boot内嵌Tomcat线程优化
高并发条件下,就是要榨干服务器的性能,而Spring Boot内嵌Tomcat默
认的线程设置比较“温柔”——默认最大等待队列为100,默认最大可连接数
为10000,默认最大工作线程数为200,默认最小工作线程数为10 。当请
求超过200+100后,会拒绝处理,当连接超过10000 后,会拒绝连接。对
于最大连接数,一般默认的10000就行了,而其它三个配置,则需要根据
需求进行优化。在application.properties里面进行修改:
1 | server.tomcat.accept-count=1000 |
- 等待队列不是越大越好,一是受到内存的限制,二是大量的出队入队操
作耗费CPU性能 - 最大线程数不是越大越好,因为线程越多,CPU上下文切换的开销越大
,存在一个“阈值”,对于一个4核8G的服务器,经验值是800
Spring Boot内嵌Tomcat网络连接优化
当然Spring Boot并没有把内嵌Tomcat的所有配置都导出。一些配置需要通
过WebServerFactoryCustomizer
口来实现自定义。这里需要自定义KeepAlive长连接的配置,减少客户端和
服务器的连接请求次数,避免重复建立连接提高性能
1 |
|
最后重新打包上传
1 | scp soquick-1.0-SNAPSHOT.jar root@60.205.106.207:/var/www/soquick/ |
分布式扩展
nginx反向代理负载均衡
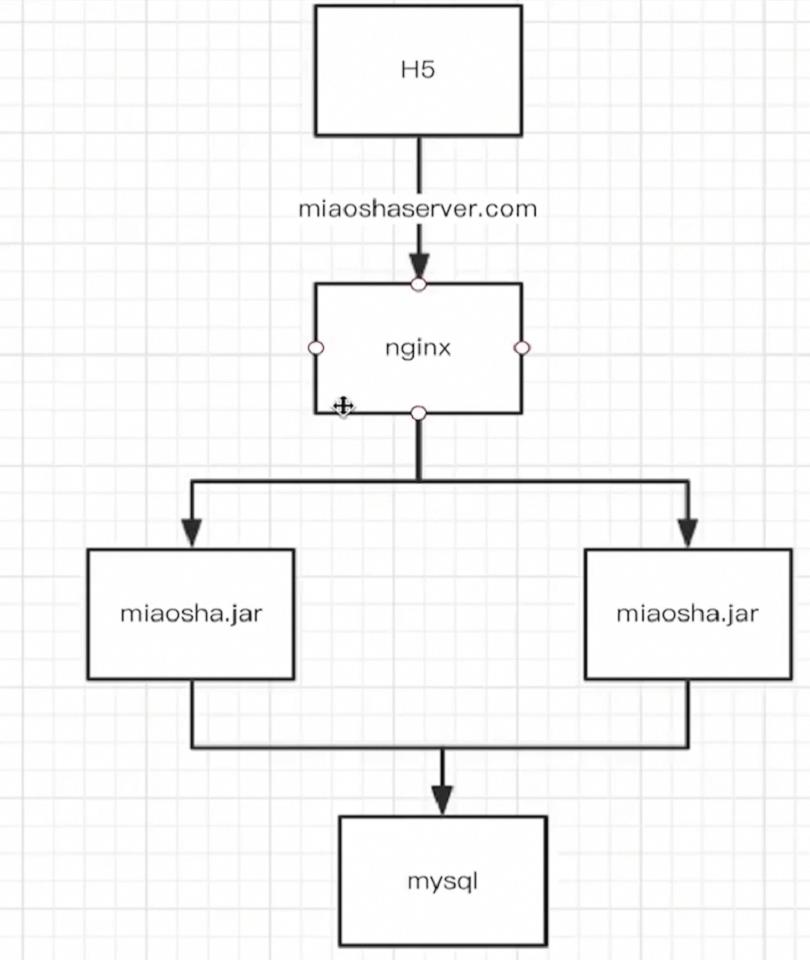
需要一台数据库服务器,两台选课项目服务器,一台反向代理服务器
1 | scp -r /var/www root@172.24.210.135:/var/ |
修改数据库权限
1 | grant all privileges on *.* to root@'%' identified by '19991005'; |
Nginx反向代理
有三个作用
- 使用nginx作为web服务器
- 使用nginx作为动静分离服务器
- 使用nginx作为反向代理服务器
安装nginx openresty
1 | scp openresty-1.13.6.2.tar.gz root@101.201.51.66:/tmp/ |
启动nginx 位置在/usr/local/openresty/nginx
1 | scp index.html root@101.201.51.66:/usr/local/openresty/nginx/html |
Nginx反向代理处理Ajax请求
Ajax请求通过Nginx反向代理到两台应用服务器,实现负载分担。在nginx.conf
里面添加以下字段:
1 | upstream backend_server{ |
这样用http://miaoshaserver访问Nginx服务器,请求会被均衡地代理
到下面的两个backend服务器上
开启Tomcat Access Log验证
开启这个功能可以查看是哪个IP发过来的请求,在application.properties
里面添加,非必须
1 | server.tomcat.accesslog.enabled=true |
分布式扩展后的效果
单机环境
多机环境
发送1000*30个请求,50us,1100TPS
Nginx高性能原因
epoll多路复用
在了解epoll多路复用之前,先看看Java BIO模型,也就是Blocking IO
阻塞模型。当客户端与服务器建立连接之后,通过Socket.write()向服务
器发送数据,只有当数据写完之后,才会发送。如果当Socket缓冲区满了
,那就不得不阻塞等待。
接下来看看Linux Select模型。该模式下,会监听一定数量的客户端连接
,一旦发现有变动,就会唤醒自己,然后遍历这些连接,看哪些连接发生
了变化,执行IO操作。相比阻塞式的BIO,效率更高,但是也有个问题,
如果10000个连接变动了1个,那么效率将会十分低下。此外,Java NIO
,即New IO或者Non-Blocking IO就借鉴了Linux Select模型。
而epoll模型,在Linux Select模型之上,新增了回调函数,一旦某个连
接发生变化,直接执行回调函数,不用遍历,效率更高
master worker进程模型
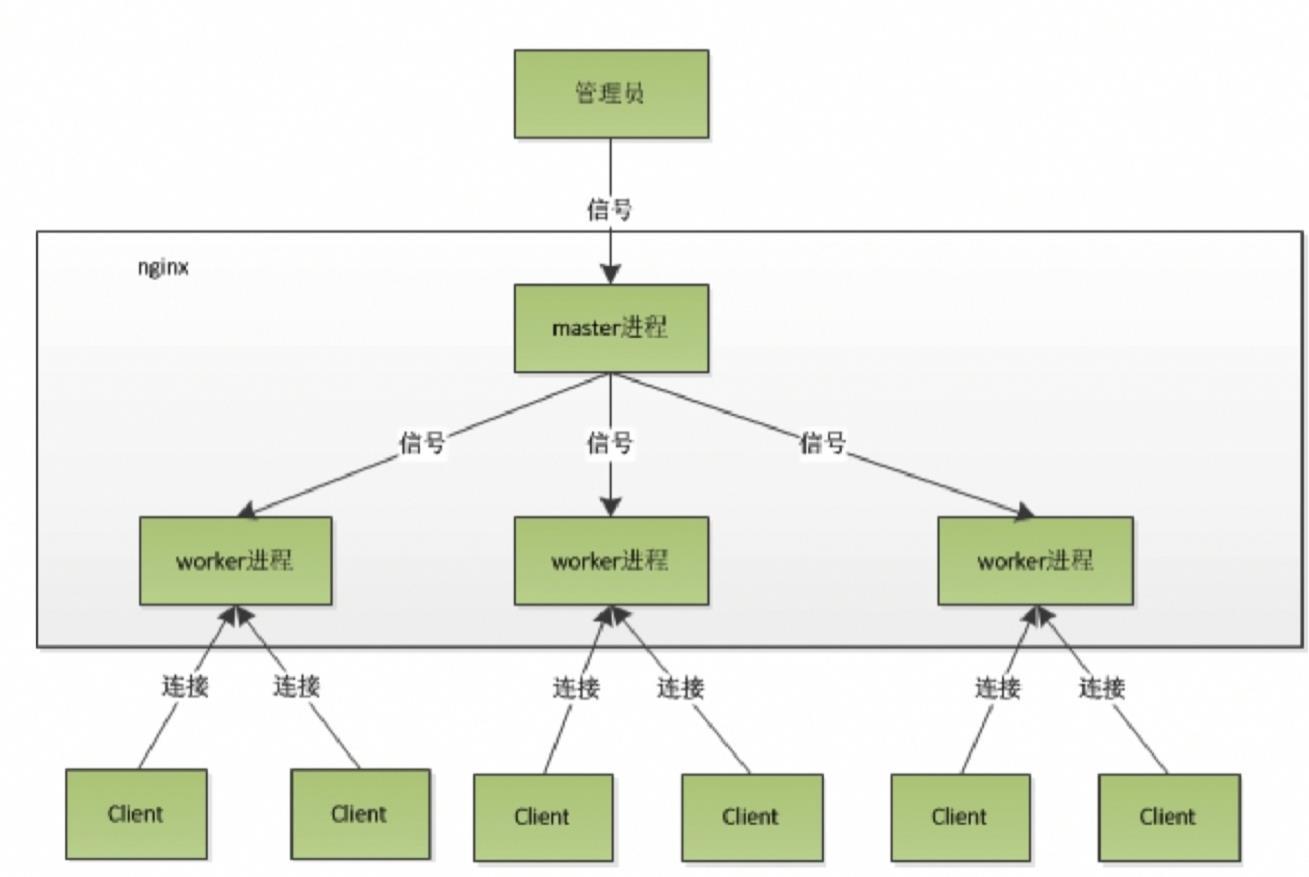
客户端的请求,并不会被master 进程处理,而是交给下面的worker 进程
来处理,多个worker进程通过“抢占”的方式取得处理权。如果某个worker
挂了,master会立刻感知到,用一个新的worker代替。这就是Nginx高效
率的原因之一,也是可以平滑重启的原理。
此外worker进程是单线程的,没有阻塞的情况下效率很高。而epoll模型避
免了阻塞。
综上epoll机制+master-worker机制使得worker进程可以高效率地执行单
线程I/O操作。
协程机制
Nginx引入了一种比线程更小的概念,那就是“协程”。协程依附于内存模型
,切换开销更小,遇到阻塞,Nginx会立刻剥夺执行权,由于在同一个线
程内,也不需要加锁
分布式会话
- 基于Cookie传输SessionId
- 基于Token传输类似SessionId
在数据库所在的阿里云服务器下载redis
1 | scp redis-5.0.4.tar.gz root@8.140.27.241:/tmp/ |
Spring Boot在Redis存入的SessionId有多项,不够简洁。一般常用UUID
生成类似SessionId的唯一登录凭证token,然后将生成的token作为KEY
,UserModel作为VALUE存入到Redis服务器
查询优化之多级缓存
多级缓存有两层含义,一个是缓存,一个是多级。我们知道,内存的速度是
磁盘的成百上千倍,高并发下,从磁盘I/O十分影响性能。所谓缓存,就是
将磁盘中的热点数据,暂时存到内存里面,以后查询直接从内存中读取,
减少磁盘I/O,提高速度。所谓多级,就是在多个层次设置缓存,一个层
次没有就去另一个层次查询
缓存设计
- 用快速存取设备,用内存
- 将缓存推到离用户最近的地方
- 脏缓存处理
多级缓存
- redis缓存
- 热点内存本地缓存
- nginx proxy cache缓存
- nginx lua 缓存
redis缓存
- 单机版
- sentinal哨兵模式
- 集群cluster模式
之前的ItemController.getItem接口,来一个Id就调用ItemService去
数据库查询一次。ItemService会查三张表,分别是课程信息表item表、
课程容量stock表和活动信息表promo,十分影响性能。
所以修改ItemController.getItem接口,思路很简单,先从Redis服务
器获取,若没有则从数据库查询并存到Redis服务。有的话直接用
序列化格式问题
采用上述方式,存到Redis里面的VALUE是类似/x05/x32的二进制格式,
我们需要自定义RedisTemplate的序列化格式。之前我们在config包下
面创建了一个RedisConfig 类,里面没有任何方法,接下来我们编写
一个方法
时间序列化格式问题
但是这样对于日期而言序列化后是一个很长的毫秒数。我们希望是yyyy
-MM-dd HH:mm:ss的格式,还需要进一步处理。新建serializer包,
里面新建两个类
本地热点缓存
Redis缓存虽好但是有网络I/O,没有本地缓存快。我们可以在Redis的前
面再添加一层“本地热点”缓存。所谓本地,就是利用本地JVM的内存。所
谓热点,由于JVM内存有限,仅存放多次查询的数据。
本地缓存,说白了就是一个HashMap,但是HashMap不支持并发读写,肯
定是不行的。juc包里面的ConcurrentHashMap虽然也能用,但是无法高
效处理过期时限、没有淘汰机制等问题,所以这里使用了Google的Guava
Cache方案。Guava Cache除了线程安全外,还可以控制超时时间,提供
淘汰机制。
先导入依赖
1 | <dependency> |
在service包下新建一个CacheService类
1 |
|
本地缓存虽快,但是也有缺点:
- 更新麻烦,容易产生脏缓存
- 受到JVM容量的限制
Nginx Proxy Cache缓存
通过Redis缓存,避免了MySQL大量的重复查询,提高了部分效率,通过本
地缓存,减少了与Redis服务器的网络I/O,提高了大量效率。但实际上,
前端(客户端)请求Nginx服务器,Nginx有分发过程,需要去请求后面
的两台应用服务器有一定网络I/O,能不能直接把热点数据存放到Nginx
服务器上呢?答案是可以的。
Nginx Proxy Cache的原理是基于文件系统的,它把后端返回的响应内容
,作为文件存放在Nginx指定目录下
- nginx反向代理前置
- 依靠文件系统存索引级的文件
- 依靠内存缓存文件地址
在nginx.conf里面配置proxy cache
1 | upstream backend_server{ |
这样当多次访问后端商品详情接口时,在nginx/tmp_cache/dir1/dir2
下生成了一个文件。cat这个文件发现就是JSON格式的数据
Nginx Proxy Cache缓存效果
发现TPS 峰值只有2800左右,平均响应时间225毫秒左右,不升反降,这
是为什么呢?原因就是,虽然用户可以直接从 Nginx 服务器拿到缓存的
数据,但是这些数据是基于文件系统的,是存放在磁盘上的,有磁盘I/O
,虽然减少了一定的网络I/O,但是磁盘I/O并没有内存快,得不偿失,
所以不建议使用
Nginx lua脚本
那Nginx有没有一种基于“内存”的缓存策略呢?答案也是有的,可以使用
Nginx lua脚本来做缓存。lua也是基于协程机制的
- 依附于线程的内存模型,切换开销小
- 遇到阻塞则释放执行权,代码同步
- 无需加锁
lua脚本可以挂载在Nginx处理请求的起始、worker进程启动、内容输出等阶段
nginx协程机制
- nginx每个工作进程创建一个lua虚拟机
- 工作进程内的所有协程共享一个vm
- 每个外部请求由一个lua协程处理,之间数据隔离
- lua代码调用io等异步接口,协程被挂起,上下文数据
lua脚本实战
在OpenResty下新建一个lua文件夹,专门用来存放lua脚本。新建一个init.lua
1 | ngx.log(ngx.ERR, "init lua success"); |
在nginx.conf里面添加一个init_by_lua_file的字段,指定上述lua脚本的
位置。当Nginx启动的时候就会执行这个lua脚本输出”init lua success”。
当然,在Nginx启动的时候,挂载lua脚本并没有什么作用。一般在内容输出阶
段,挂载lua脚本。新建一个staticitem.lua,用ngx.say()输出一段字符串
。在nginx.conf里面添加一个新的location:
1 | location /staticitem/get{ |
访问/staticitem/get,在页面就会响应出staticitem.lua的内容。
新建一个helloworld.lua,使用ngx.exec(“/item/get?id=1”)访问某个
URL。同样在nginx.conf里面添加一个helloworldlocation。这样,当访
问/helloworld的时候就会跳转到item/get?id=8这个URL上
OpenResty
- OpenResty由Nginx核心加很多第三方模块组成,默认集成了Lua开发环境
,使得Nginx可以作为一个Web Server使用 - 借助于Nginx的事件驱动模型和非阻塞IO,可以实现高性能的Web应用程序
- OpenResty提供了大量组件如Mysql、Redis、Memcached等,使在Nginx上
开发Web应用更方便更简单
Shared dict
OpenResty的Shared dict是一种类似于HashMap的Key-Value内存结构,对
所有worker进程可见,并且可以指定LRU淘汰规则。和配置proxy cache一样
,我们需要指定一个名为my_cache,大小为128m的lua_shared_dict
1 | upstream backend_server |
在lua文件夹下,新建一个itemsharedict.lua脚本,编写两个函数
1 | function get_from_cache(key) |
然后编写main函数
1 | --得到请求的参数,类似Servlet的request.getParameters |
新建一个luaitem/get的location,注意default_type是json
1 | location /luaitem/get{ |
Shared dict缓存效果
压测/luaitem/get,峰值TPS在4000左右,平均响应时间150ms左右,比
proxy cache要高出不少,跟使用两层缓存效果差不多。
使用Ngxin的Shared dict,把压力转移到了Nginx服务器,后面两个Tomcat
服务器压力减小。同时减少了与后面两个Tomcat服务器、Redis服务器和数据
库服务器的网络I/O,当网络I/O成为瓶颈时,Shared dict不失为一种好方
法。最后,Shared dict依然受制于缓存容量和缓存更新问题
Redis支持
新建一个itemredis.lua
1 | local args=ngx.req.get_uri_args() |
页面静态化
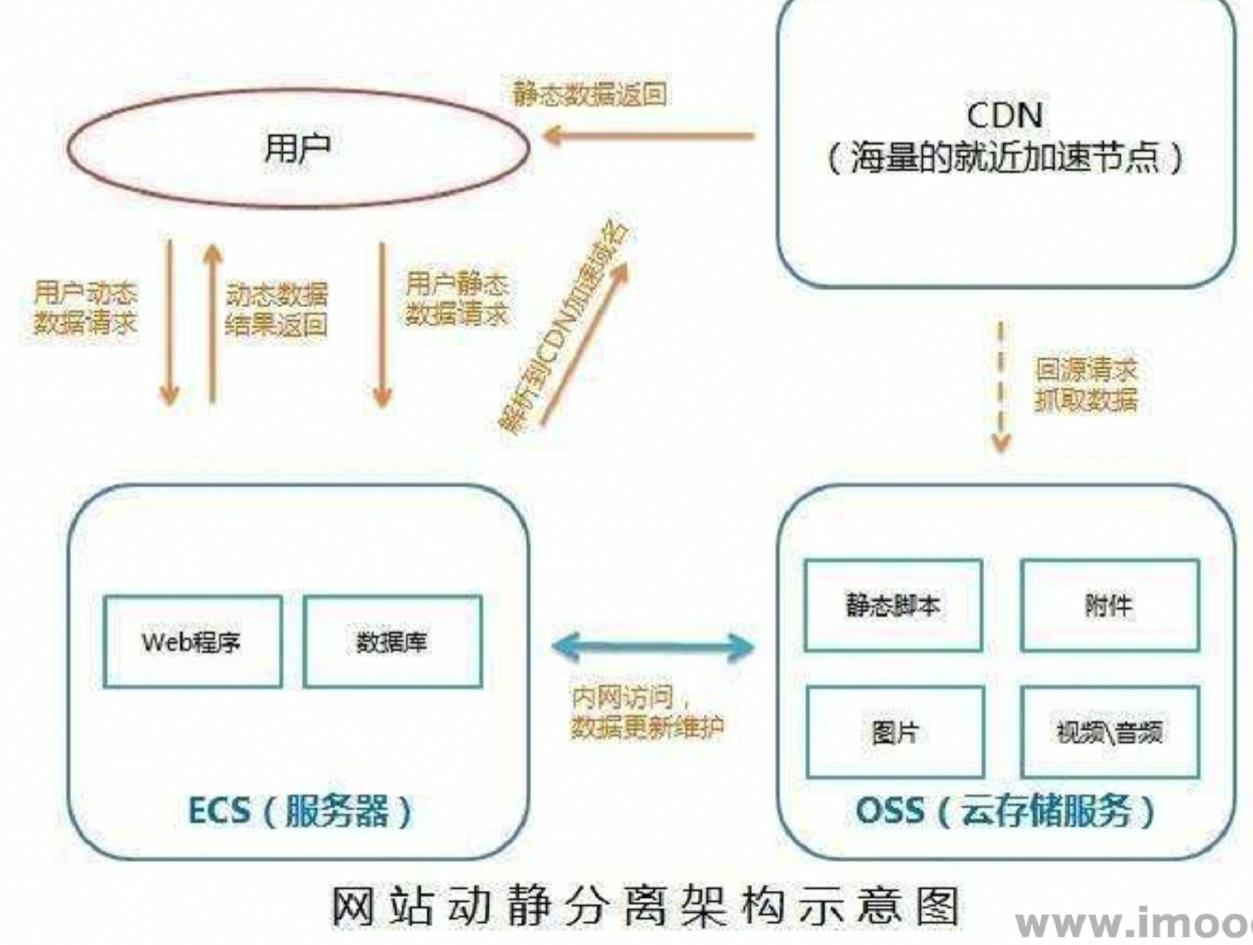
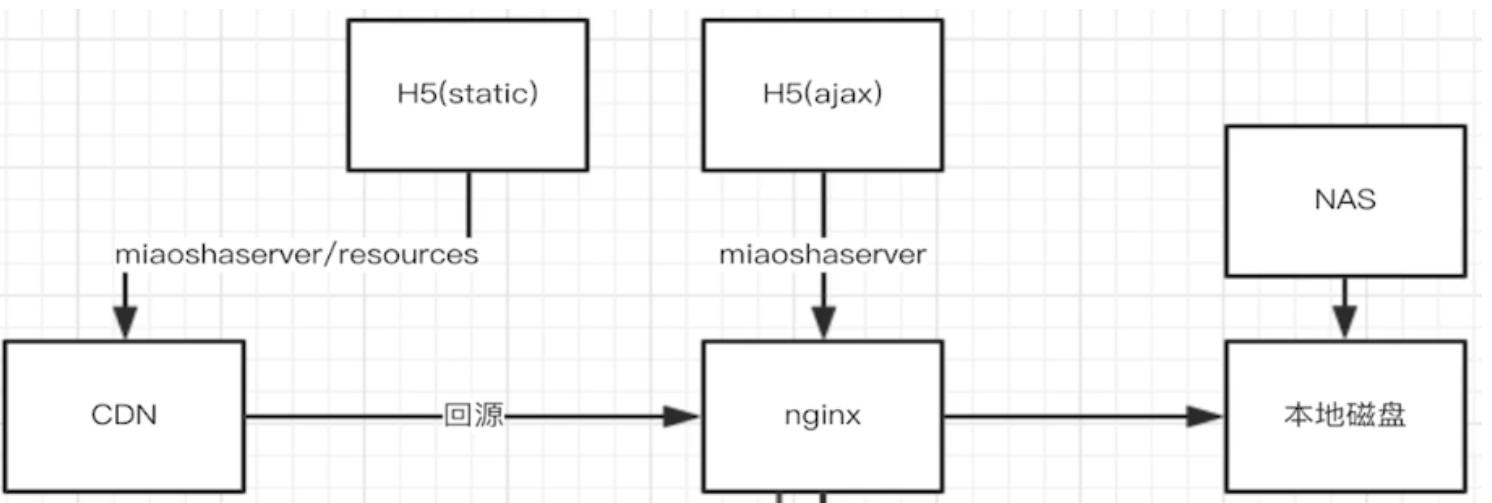
之前静态资源是直接从Nginx服务器上获取,而现在会先去CDN服务器上
获取,如果没有则回源到Nginx服务器上获取
CDN
CDN是内容分发网络,一般用来存储(缓存)项目的静态资源。访问静态
资源,会从离用户最近的CDN服务器上返回静态资源。如果该CDN服务器
上没有静态资源,则会执行回源操作,从Nginx服务器上获取静态资源
cache controll响应头
在响应里面有一个cache controll响应头,这个响应头表示客户端是否
可以缓存响应。有以下几种缓存策略 
选择缓存策略
如果不缓存,那就选择no-store。如果需要缓存,但是需要重新验证,则
选择no-cache,如果不需要重新验证,则选择private或者public。然后
设置max-age,最后添加ETag Header 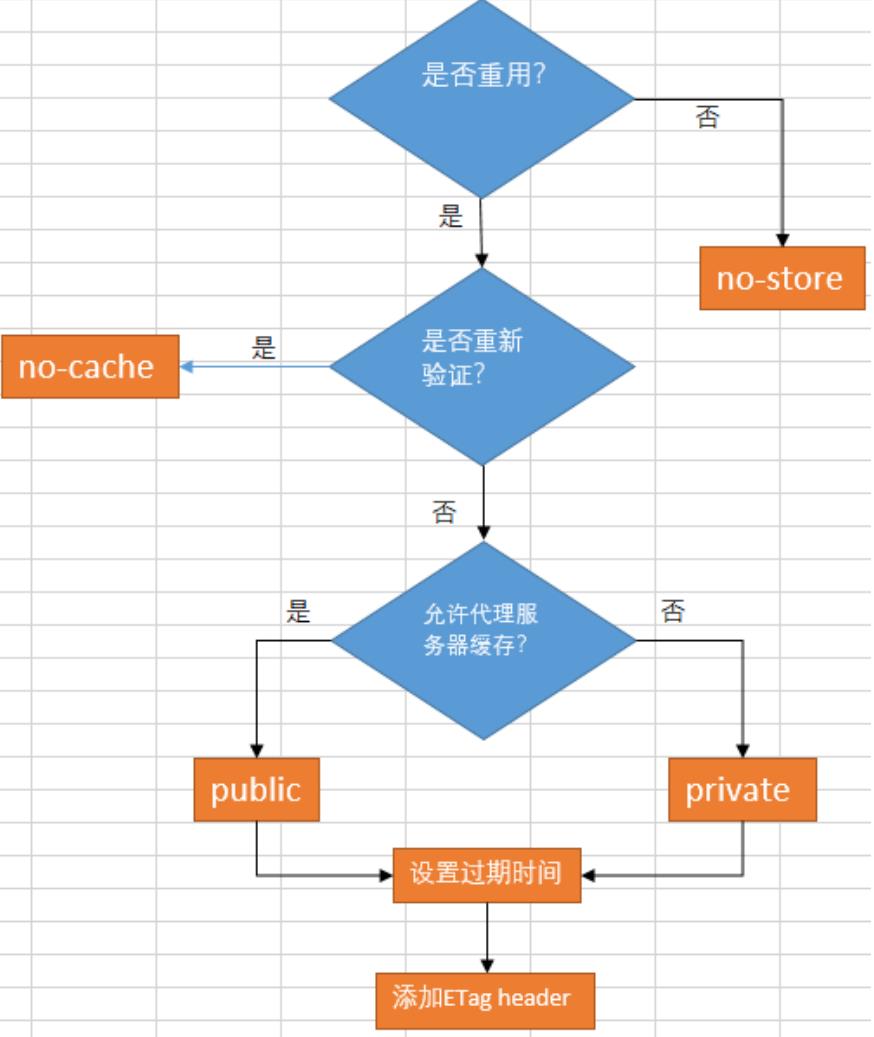
有效性验证
如果不缓存,那就选择no-store。如果需要缓存,但是需要重新验证,则
选择no-cache,如果不需要重新验证,则选择private或者public。然后
设置max-age,最后添加ETag Header 
有效性验证
ETag:第一次请求资源的时候,服务器会根据资源内容生成一个唯一标示
ETag,并返回给浏览器。浏览器下一次请求会把ETag(If-None-Match)
发送给服务器,与服务器的ETag进行对比。如果一致就返回一个304响应
,即Not Modify,表示浏览器缓存的资源文件依然是可用的,直接使用
就行了不用重新请求。请求资源的流程如下 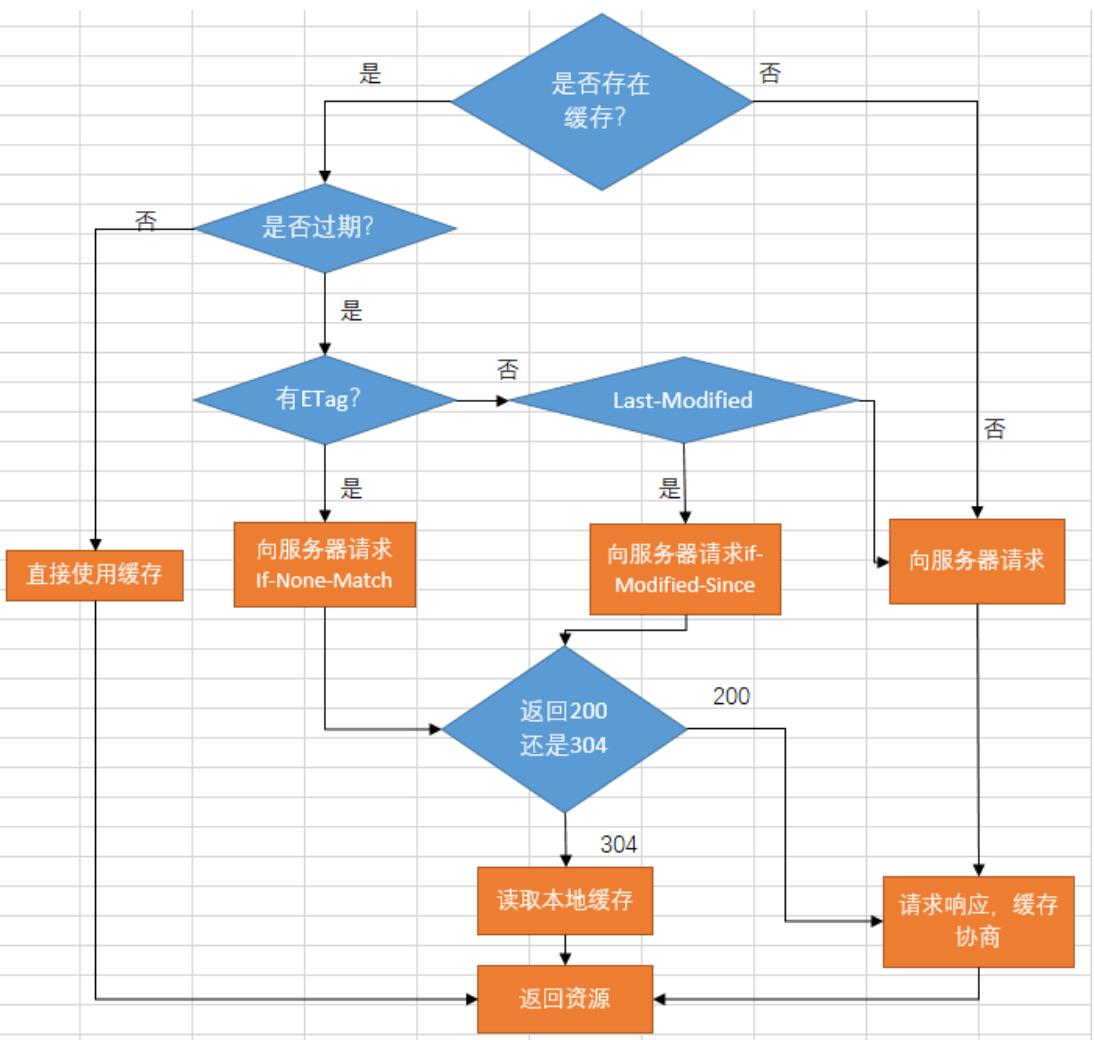
浏览器三种刷新方式
- a标签/回车刷新
查看max-age是否有效,有效直接从缓存中获取,无效进入缓存协商逻辑 - F5刷新
取消max-age或者将其设置为0,直接进入缓存协商逻辑 - CTRL+F5强制刷新
直接去掉cache-control和协商头,重新请求资源
自定义缓存策略
CDN服务器既充当了浏览器的服务端,又充当了Nginx的客户端。所以它的
缓存策略尤其重要。除了按照服务器的max-age,CDN服务器还可以自己设
置过期时间。
总的规则就是:源站没有配置,遵从CDN控制台的配置;CDN控制台没有配
置,遵从服务器提供商的默认配置。源站有配置,CDN控制台有配置,遵从
CDN控制台的配置。CDN控制台没有配置,遵从源站配置 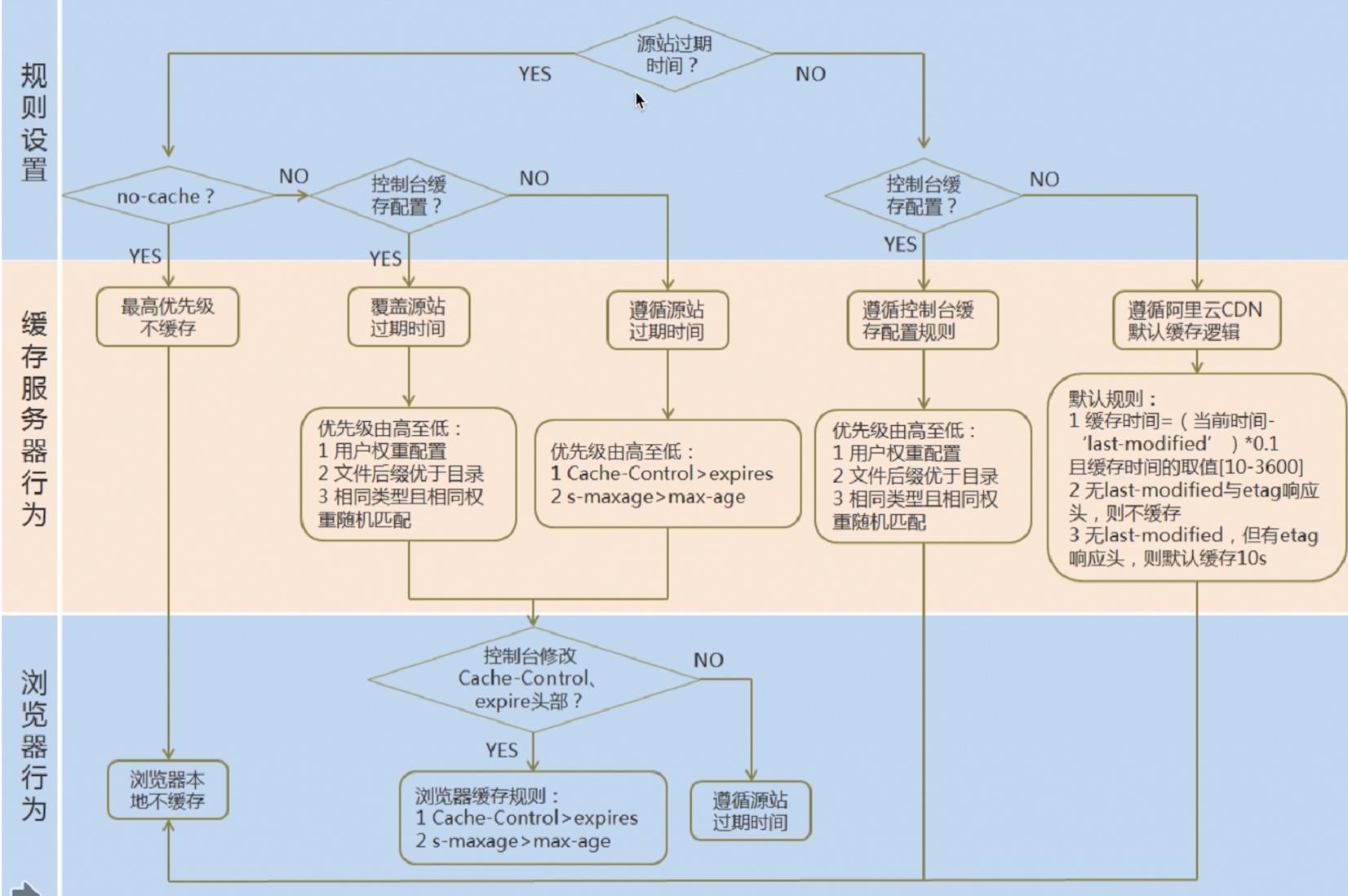
静态资源部署策略
假如服务器端的静态资源更新了,但是由于客户端的max-age还未失效,
用的还是老的资源,文件名又一样,用户不得不使用CTRL+F5强制刷新,
才能请求更新的静态资源。解决方法有三种
- 版本号:在静态资源文件后面追加一个版本号,比如a.js?v=1.0。这种
方法维护起来十分麻烦,比如只有一个js文件做了修改,那其它html、css
文件要不要追加版本号呢? - 摘要:对静态资源的内容进行哈希操作,得到一个摘要,比如a.js?v=
45edw,维护起来更加方法。但是会导致是先部署js还是先部署html的问题
。比如先部署js,那么html页面引用的还是老的js,js直接失效。如果先
部署html,那么引用的js又是老版本的js - 摘要作为文件名:比如45edw.js,会同时存在新老两个版本,方便回滚
全页面静态化
现在的架构是,用户通过CDN请求到了静态资源,然后静态页面会在加载的
时候,发送一个Ajax请求到后端,接收到后端的响应后,再用DOM渲染。也
就是每一个用户请求,都有一个请求后端接口并渲染的过程。那能不能取消
这个过程直接在服务器端把页面渲染好,返回一个纯html文件给客户端呢?
全页面静态化就是在服务端完成html css甚至js的load渲染成纯html文件
后直接以静态资源的方式部署在cdn上
phantomJS
phantomJS就像一个爬虫,会把页面中的JS执行完毕后,返回一个渲染完
成的html文件
交易优化
发送20*200个请求压测createOrder接口,TPS只有280左右,平均响应时
间460毫秒。应用服务器us占用高达75%,1分钟的load average高达2.21
,可见压力很大。相反,数据库服务器的压力则要小很多。
原因在于,在OrderService.createOrder方法里面,首先要去数据库查询
商品信息,而在查询商品信息的过程中,又要去查询秒杀活动信息,最后还
要查询用户信息
1 | //查询商品信息的过程中,也会查询秒杀活动信息。 |
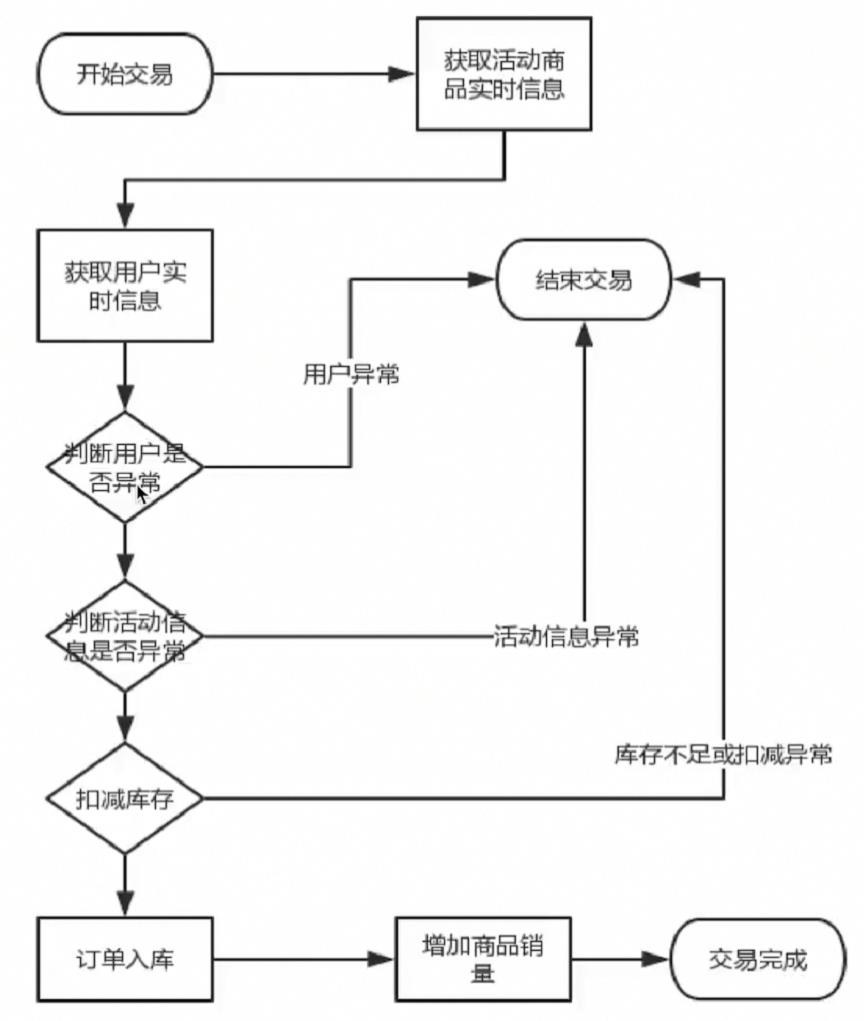
这还没完,最后还要对stock库存表进行-1 update操作,对order_info
订单信息表进行添加insert操作,对item商品信息表进行销量+1update
操作。仅仅一个下单,就有6次数据库I/O操作,此外,减库存操作还存在
行锁阻塞,所以下单接口并发性能很低
交易验证优化
查询用户信息,是为了用户风控策略。判断用户信息是否存在是最基本的
策略,在企业级中,还可以判断用户状态是否异常,是否异地登录等等
。用户风控的信息,实际上可以缓存化,放到Redis里面。
查询商品信息、活动信息,是为了活动校验策略。商品信息、活动信息,也
可以存入缓存中。活动信息,由于具有时效性,需要具备紧急下线的能力
,可以编写一个接口,清除活动信息的缓存
用户校验缓存优化
思路很简单,就是先从Redis里面获取用户信息,没有再去数据库里查,并
存到Redis里面。UserService新开一个getUserByIdInCache的方法
1 | public UserModel getUserByIdInCache(Integer id) { |
活动校验缓存优化
跟用户校验类似,ItemService新开一个getItemByIdInCache方法
1 | public ItemModel getItemByIdInCache(Integer id) { |
库存扣减优化
索引优化
之前扣减库存的操作,会执行update stock set stock=stock-#{amount}
where item_id = #{itemId} and stock >= #{amount}这条SQL语句。如
果where条件的item_id字段没有索引那么会锁表性能很低。
所以先查看item_id字段是否有索引,没有的话,使用alter table stock
add UNIQUE INDEX item_id_index(item_id),为item_id字段添加一个
唯一索引,这样在修改的时候,只会锁行
1 | alter table item_stock add UNIQUE INDEX item_id_index(item_id) |
库存扣减缓存优化
串行话减库存无法避免,之前下单是直接操作数据库,一旦秒杀活动开始,
大量的流量涌入扣减库存接口,数据库压力很大。那么可不可以先在缓存中
下单?答案是可以的。如果要在缓存中扣减库存,需要解决两个问题,第一
个是活动开始前,将数据库的库存信息,同步到缓存中。第二个是下单之后
,要将缓存中的库存信息同步到数据库中。这就需要用到异步消息队列——
也就是RocketMQ
同步数据库库存到缓存
PromoService新建一个publishPromo的方法,把数据库的缓存存到Redis
里面去
- 活动发布同库存进缓存
- 下单交易减缓存库存这里需要注意的是,当我们把库存存到Redis的时候,商品可能被下单,
1
2
3
4
5
6
7
8
9
10public void publishPromo(Integer promoId) {
//通过活动id获取活动
PromoDO promoDO=promoDOMapper.selectByPrimaryKey(promoId);
if(promoDO.getItemId()==null || promoDO.getItemId().intValue()==0)
return;
ItemModel itemModel=itemService.getItemById(promoDO.getItemId());
//库存同步到Redis
redisTemplate.opsForValue().set("promo_item_stock_"+itemModel.getId()
,itemModel.getStock());
}
这样数据库的库存和Redis的库存就不一致了。解决方法就是活动未开始
的时候,商品是下架状态,不能被下单。在ItemController中添加相应
的功能最后在ItemService里面修改decreaseStock方法,在Redis里面扣减库存1
2
3
4
5
6(value = "/publishpromo",method = {RequestMethod.GET})
public CommonReturnType publishpromo(@RequestParam(name = "id")Integer id){
promoService.publishPromo(id);
return CommonReturnType.create(null);
}1
2
3
4
5
6
7public boolean decreaseStock(Integer itemId, Integer amount) {
// 老方法,直接在数据库减
// int affectedRow=itemStockDOMapper.decreaseStock(itemId,amount);
long affectedRow=redisTemplate.opsForValue().
increment("promo_item_stock_"+itemId,amount.intValue()*-1);
return (affectedRow >= 0);
}
同步缓存库存到数据库(异步扣减库存)
以上的问题是数据库记录不一致,RocketMQ是阿里巴巴在RabbitMQ基础
上改进的一个消息中间件,特点如下
- 高性能、高并发、分布式消息中间件
- 典型应用场景:分布式事务,异步解耦
概念模型 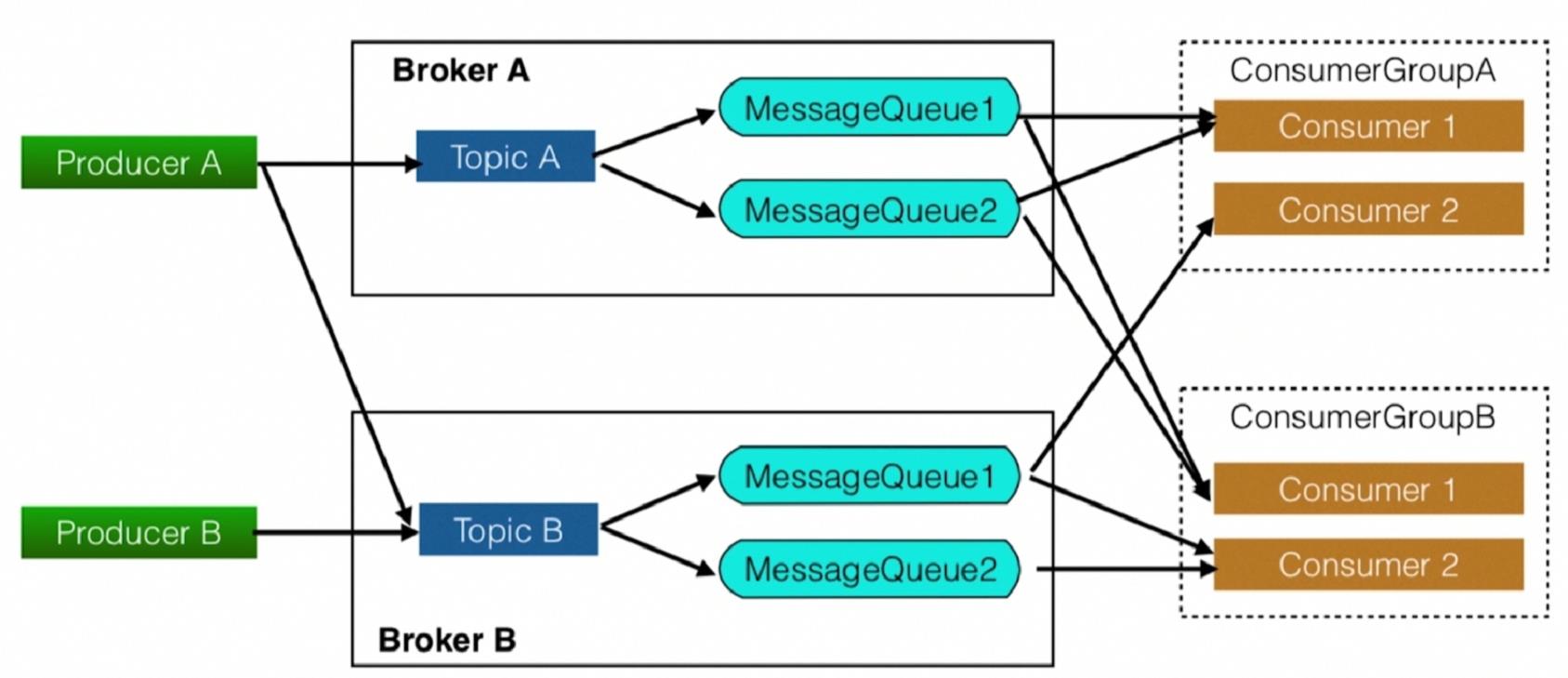 部署模型
部署模型 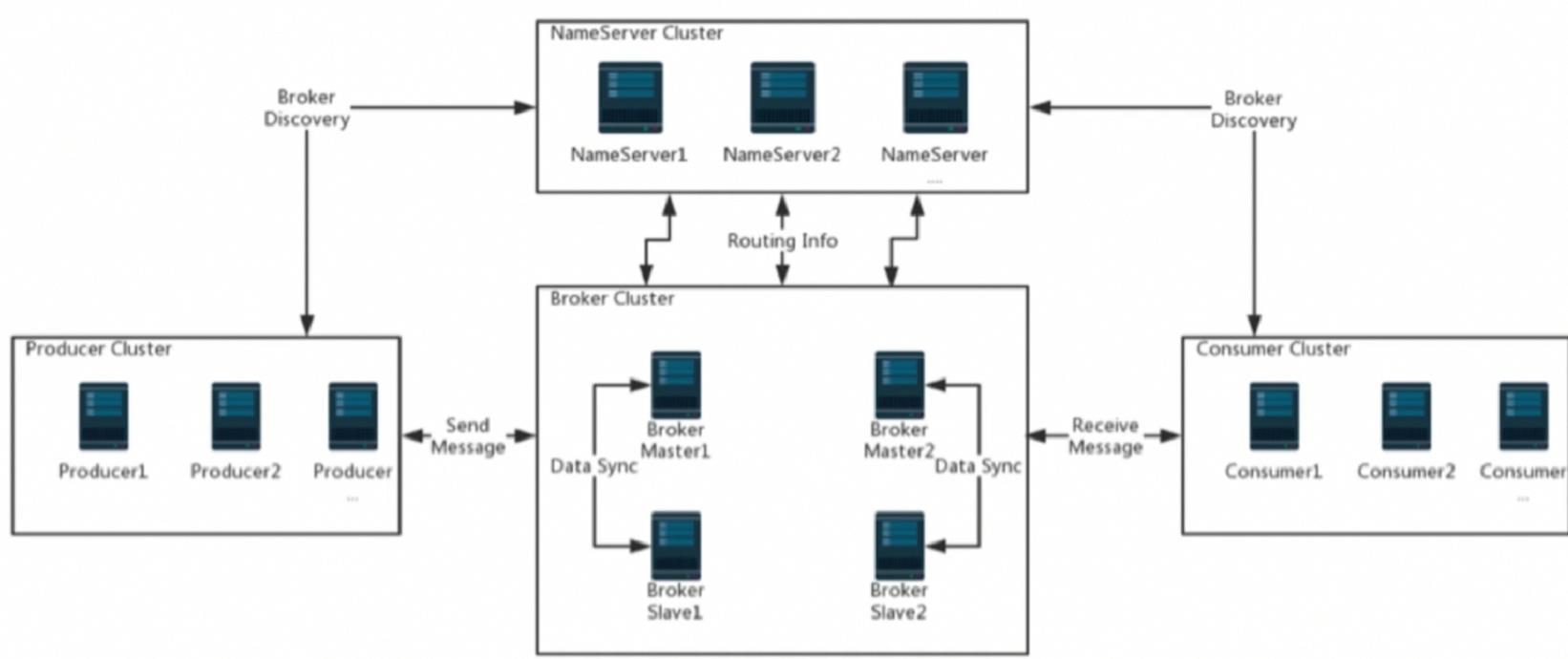
下载rocketmq
1 | scp rocketmq-all-4.4.0-bin-release.zip root@8.140.27.241:/var/www/rocketmq/ |
新建一个mq包,创建两个类:一个生产者一个消费者。然后在pom.xml
中导入依赖
1 | <dependency> |
编写asyncReduceStock方法,实现异步扣减库存
1 | public boolean asyncReduceStock(Integer itemId, Integer amount) { |
如果发送消息失败那么需要把库存恢复
1 | public boolean decreaseStock(Integer itemId, Integer amount) { |
异步扣减库存存在的问题
- 如果发送消息失败,只能回滚Redis
- 消费端从数据库扣减操作执行失败,如何处理(这里默认会成功)
- 下单失败无法正确回补库存(比如用户取消订单)